TL;DR: Kafka is a distributed streaming platform that stores event data in topics and partitions across a cluster of brokers. Producers publish events, consumer groups process them independently, and replication across brokers ensures durability and fault tolerance.
Introduction
Kafka architecture describes how Apache Kafka is structured to capture, store, and distribute streams of real-time event data across distributed systems. Understanding Kafka architecture helps architects and developers design scalable streaming platforms, event-driven systems, and real-time data pipelines.
Kafka architecture is designed to move large volumes of real-time data between applications, services, and data platforms. The architecture emphasizes horizontal scalability, durability, and high throughput so organizations can process continuous streams of operational data.
In a Kafka cluster, events are written to topics that are split into partitions and distributed across brokers. Applications publish events to Kafka and other systems consume those events independently. This decoupled design allows teams to scale systems, add new consumers, and evolve data pipelines without tightly coupling producers and consumers.
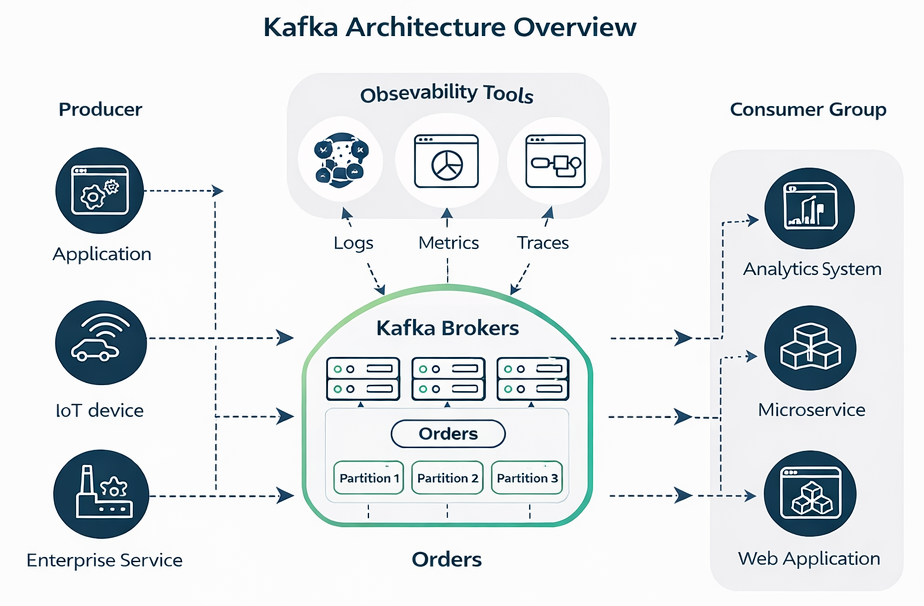 Figure: Kafka architecture overview showing producers, brokers, topics, partitions, and consumer groups.
Figure: Kafka architecture overview showing producers, brokers, topics, partitions, and consumer groups.
Kafka Architecture at a Glance
This quick reference summarizes the core pieces of Kafka architecture before diving into the detailed explanation of how they work together.
| Component | Role in Kafka Architecture |
|---|---|
| Producer | Publishes events into Kafka topics |
| Broker | Kafka server that stores partitions and serves client requests |
| Topic | Logical stream of related events |
| Partition | Ordered log that enables horizontal scalability |
| Consumer | Application that reads events from topics |
| Consumer Group | Mechanism that allows multiple consumers to process partitions in parallel |
Core Components of Kafka Architecture
Kafka architecture is built from several fundamental components that work together to move data reliably across distributed systems.
Brokers
A broker is a Kafka server responsible for storing data and serving client requests. Each broker manages partitions of topics and handles communication with producers and consumers.
Brokers form a cluster. Within that cluster, partitions are distributed across multiple nodes so the workload can scale horizontally. As data volumes increase, additional brokers can be added to the cluster.
Topics
Topics represent logical streams of events. Applications publish events to a topic and consumers subscribe to the topics they are interested in processing, so it is important to design topic naming conventions for event-driven microservices that support scalable routing and governance.
A topic might represent:
- orders created in an ecommerce system
- payment transactions
- user activity events
- telemetry from devices
Topics act as the central communication channel between producers and consumers.
Partitions
Partitions are the unit of parallelism and scalability within Kafka. Each topic is divided into one or more partitions, and each partition is an ordered log of records.
Partitions allow Kafka to distribute data across multiple brokers and enable consumers to process data concurrently.
Producers
Producers are applications that publish events to Kafka topics. They determine which topic an event belongs to and may also choose the partition where the event will be written.
Producers typically include:
- backend services
- microservices
- applications generating events
- IoT devices
Consumers
Consumers read events from Kafka topics. They subscribe to one or more topics and process events as they are received.
Consumers keep track of their position in the log using offsets. This allows them to resume processing from the correct location if they restart.
Consumer Groups
Consumer groups allow Kafka to scale consumption of event streams. Within a consumer group, each partition is processed by only one consumer at a time.
This model enables parallel processing while ensuring that events from a partition are handled in order.
Kafka Cluster Architecture
Kafka operates as a distributed cluster of brokers. Partitions are spread across these brokers so that data and workloads are distributed evenly.
Replication across brokers ensures that the system remains available even if a server fails. Clusters can scale from a few nodes to hundreds depending on throughput requirements.
Example Kafka Cluster Design
To understand Kafka architecture in practice, consider a simple production cluster.
Example cluster configuration:
- Three brokers forming a Kafka cluster
- One topic named orders
- Six partitions to allow parallel processing
- Replication factor of three so each partition exists on three brokers
In this design, every partition has one leader and two followers distributed across the brokers. Producers write to the leaders, while followers replicate the data. Consumer groups then process partitions in parallel across multiple consumer instances.
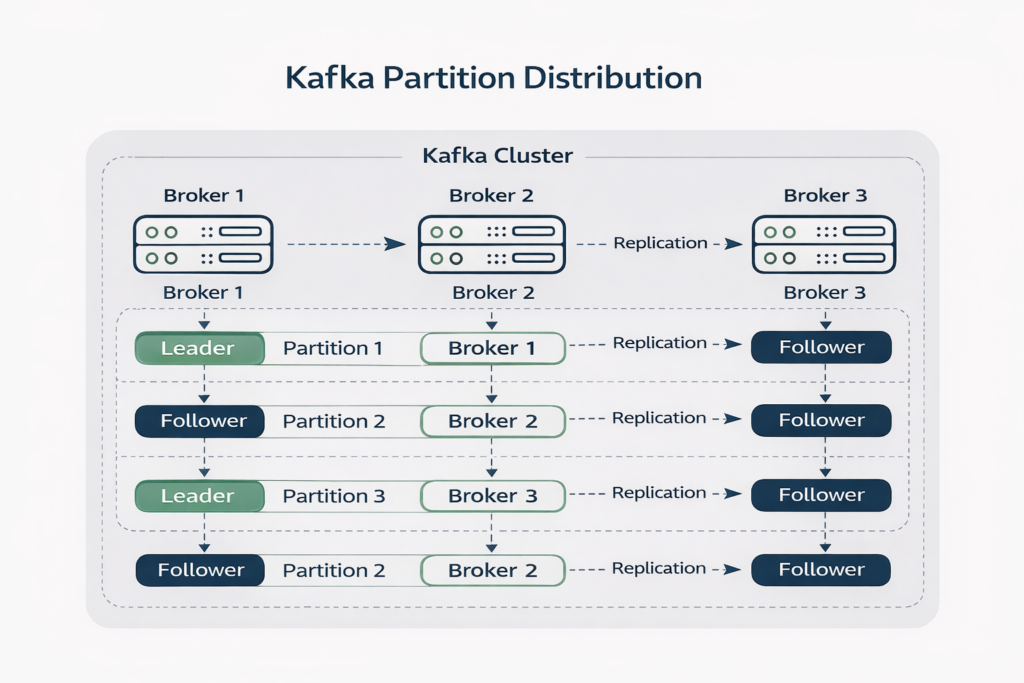 Figure: Topic partitions distributed across multiple brokers with replication.
Figure: Topic partitions distributed across multiple brokers with replication.
This design allows the system to tolerate broker failures while maintaining high throughput.
Leaders and Followers
Each partition in Kafka has one leader replica and one or more follower replicas.
The leader handles read and write requests from clients. Followers replicate the data from the leader so that a copy of the data exists on multiple brokers.
If a leader broker fails, one of the followers automatically becomes the new leader. This process ensures high availability and protects against data loss.
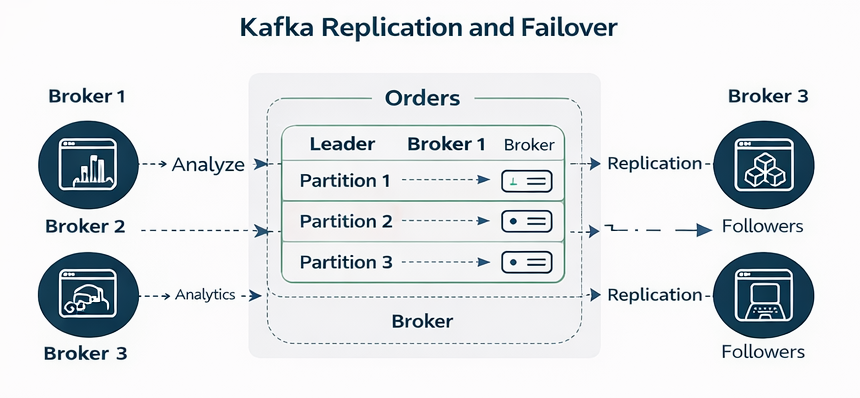 Figure: Partition replication across brokers with leader and follower replicas and automatic failover.
Figure: Partition replication across brokers with leader and follower replicas and automatic failover.
Kafka Data Flow
Kafka architecture moves events through the system in a predictable sequence.
- A producer publishes an event to a topic.
- The broker receives the event and writes it to the appropriate partition.
- Replicas copy the data across brokers.
- Consumers read events from the partition log.
- Applications process the events and update downstream systems.
This append-only log structure allows Kafka to deliver very high throughput while maintaining durable storage.
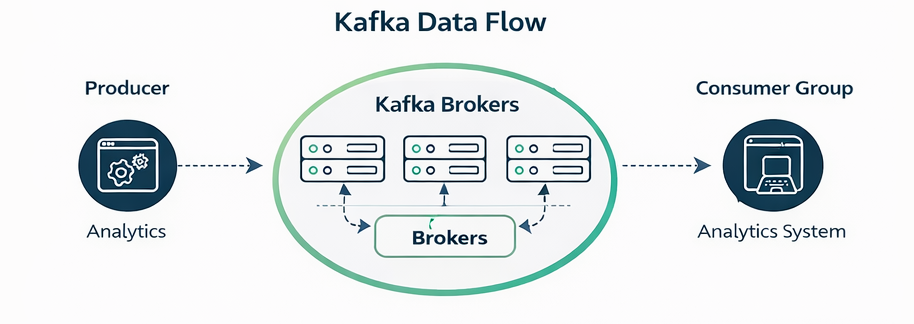 Figure: Event flow from producers through Kafka brokers and partitions to consumer groups.
Figure: Event flow from producers through Kafka brokers and partitions to consumer groups.
Storage and Processing Layers
Kafka architecture can be viewed as two logical layers: storage and compute.
Storage Layer
Kafka stores events in append-only logs on disk. Writes occur sequentially, which allows the system to achieve very high write performance even with large data volumes.
Events remain available for a configured retention period, allowing consumers to replay historical data when needed.
Compute Layer
Processing is performed by consumers and stream processing frameworks that read from Kafka.
Examples include:
- stream analytics systems
- data transformation pipelines
- machine learning feature pipelines
Separating storage from processing allows Kafka to act as a durable event backbone for many independent systems.
Architectural Patterns Enabled by Kafka
Kafka is often used to support several architectural patterns common in modern distributed systems. However, it is important to understand how Kafka implements these patterns in practice, because its log‑based architecture differs from true real‑time publish/subscribe systems.
Event-Driven Architecture
For readers new to the broader paradigm, a complete guide to event-driven architecture can provide additional context on how these concepts apply beyond Kafka.
Event‑driven architecture (EDA) is built around the idea that systems react to events as they occur. A service emits an event when something meaningful happens, and other services respond immediately, which comes with event-driven architecture pros and cons that architects must weigh when adopting Kafka.
Kafka can approximate the behavior of EDA by acting as the central event log that services publish events into and consume events from. However, Kafka consumers typically pull events from partitions rather than receiving them through direct push delivery. In practice, this means Kafka behaves more like a high‑throughput event log that applications poll continuously, so architects must carefully design events, schemas, and payloads in EDA systems to keep producers and consumers decoupled.
This design still enables loosely coupled services and asynchronous communication, but it differs from low‑latency broker‑based publish/subscribe systems where events are pushed directly to subscribers as they occur, especially when those systems are built as enterprise-wide event-driven architectures with event mesh across hybrid and multi-cloud environments.
Streaming Data Pipelines
Kafka architecture is particularly well suited for streaming data pipelines. Because Kafka stores events in durable logs, multiple systems can read the same stream of events independently and process them at different speeds, and many organizations pair Kafka with complementary Solace event brokers working together with Kafka to bridge real-time messaging with durable streaming.
A typical pipeline might move data from operational databases into stream processing engines and eventually into data warehouses, analytics platforms, or machine learning pipelines. Kafka’s partitioned log structure allows these pipelines to process large data volumes in parallel.
Microservices Integration
Kafka is also widely used to connect microservices. Instead of making synchronous service‑to‑service calls, applications publish events describing state changes and other services consume those events to update their own state, often combining Kafka with established event-driven architecture patterns like CQRS and event sourcing.
This model reduces tight coupling between services and improves resilience. However, because consumers pull events from the log, applications must still manage polling intervals, offsets, and consumer group coordination when building microservice architectures on Kafka.
ZooKeeper and the Evolution to KRaft
For many years, Kafka relied on Apache ZooKeeper as an external coordination system. ZooKeeper was responsible for managing critical cluster metadata and coordination tasks that Kafka brokers themselves could not originally perform.
ZooKeeper handled several key responsibilities:
- Tracking which brokers were currently part of the cluster
- Selecting the leader replica for each partition
- Storing configuration information about topics, partitions, and replicas
- Determining which broker acts as the cluster controller
In this architecture, every Kafka cluster required a separate ZooKeeper ensemble. Brokers communicated with ZooKeeper to update metadata, detect failures, and coordinate partition leadership changes.
While this model worked well for early Kafka deployments, it introduced several operational challenges. Running a ZooKeeper cluster added additional infrastructure to manage, required specialized operational knowledge, and created another distributed system that could fail independently of Kafka itself.
As Kafka adoption grew and clusters became larger, these limitations became more significant. Large installations sometimes experienced metadata scalability issues or operational complexity caused by the tight coupling between Kafka and ZooKeeper.
To address these limitations, the Kafka community introduced KRaft (Kafka Raft metadata mode). KRaft removes the ZooKeeper dependency and integrates metadata management directly into Kafka using the Raft consensus protocol.
In KRaft mode, a subset of brokers act as controllers. These controllers form a Raft quorum that manages cluster metadata, including broker membership, topic configuration, and partition leadership.
Instead of storing metadata in ZooKeeper, Kafka stores it in an internal metadata log that is replicated across the controller quorum. Changes to cluster state—such as topic creation, partition reassignment, or broker failure—are written to this log and replicated using the Raft protocol.
Key improvements introduced by KRaft include:
- Elimination of ZooKeeper so Kafka clusters no longer require a separate coordination system
- Simpler operations because only Kafka brokers need to be deployed and managed
- Better scalability for large clusters with thousands of partitions and brokers
- Stronger metadata consistency through Raft-based consensus and replicated metadata logs
Because metadata is now stored and replicated directly within Kafka, the architecture becomes easier to operate and scale.
Modern Kafka deployments are increasingly moving toward KRaft-based clusters, and newer Kafka releases are designed with this architecture in mind. Over time, KRaft is expected to fully replace ZooKeeper as the standard metadata management model for Kafka.
Kafka Architecture Best Practices
Designing an effective Kafka deployment requires careful planning across capacity, resilience, and operational visibility. Because Kafka distributes data across partitions and brokers, architectural decisions made early—such as partition count and replication strategy—can have a significant impact on scalability and operational stability later.
Several considerations are particularly important when designing Kafka clusters:
- Choosing an appropriate number of partitions so workloads can scale without creating unnecessary coordination overhead
- Setting the correct replication factor to balance durability with storage and network costs
- Planning for multi-datacenter or multi-region deployments when availability requirements demand geographic resilience
- Implementing monitoring and observability to track broker health, replication lag, and consumer performance
Large Kafka deployments often extend the core platform with additional ecosystem tools. Schema registries help manage evolving data formats, connectors move data between Kafka and external systems, and stream processing frameworks perform transformations and real-time analytics on event streams.
When Kafka Architecture Works Best
Kafka architecture is most effective in environments where large volumes of event data must be captured once and consumed by many systems.
Common use cases include:
- Real-time data pipelines that move operational data into analytics platforms or data warehouses
- Event-driven microservices where services publish state changes and other services react asynchronously
- Log aggregation platforms that collect operational events from many applications
- IoT systems that ingest telemetry from large fleets of connected devices
- Real-time analytics platforms processing continuous event streams
Enterprise platforms such as SAP increasingly adopt advanced event mesh for SAP event-driven architectures to connect these Kafka-based streams with core business applications.
In these scenarios Kafka acts as a central event backbone. Data is written once and can be consumed by many downstream systems at different speeds, enabling analytics, automation, and operational services to run on the same event streams.
This model is particularly valuable when multiple teams or systems need access to the same stream of operational events without tightly coupling producers and consumers.
Kafka Architecture vs Event Broker Architecture
Kafka is often described as a publish/subscribe system, but its architecture differs from traditional event broker platforms in several important ways, as highlighted when comparing Solace and Kafka architectures.
Traditional event brokers deliver events to subscribers as soon as they occur. The broker pushes messages directly to connected consumers with very low latency. This model is commonly used for operational systems that require immediate reaction to events.
Kafka instead centers on a distributed event log. Producers append events to partitions, and consumers retrieve those events by reading from the log. In most deployments, consumers continuously poll partitions to fetch new records.
Both approaches support loosely coupled systems, but they optimize for different goals. Key architectural differences include:
- Delivery model: Event brokers push events to subscribers, while Kafka consumers pull events from partition logs.
- Primary abstraction: Event brokers center on topics and subscriptions, while Kafka centers on partitions within an append‑only log.
- Latency model: Push delivery can enable very low latency reaction to events, while Kafka prioritizes high throughput and scalable log storage.
- Replay capability: Kafka allows consumers to replay historical data from retained logs, whereas many brokers deliver events once and then discard them.
Because of these differences, Kafka is often used as the streaming backbone for data pipelines and analytics platforms, while broker‑based publish/subscribe systems are frequently used for operational event distribution between applications and services.
Understanding this distinction helps architects choose the right technology for real‑time event processing, integration, and large‑scale data streaming.
Limitations of Kafka Architecture
Although Kafka is powerful, its architecture introduces operational complexity. Managing partitions, scaling clusters, and operating distributed infrastructure requires significant expertise.
Organizations often extend Kafka with additional technologies to simplify integration patterns, improve governance, or support broader event distribution across complex environments.
How Kafka Components Work Together
Understanding Kafka architecture becomes easier when you look at how the core components interact during normal operation.
A producer publishes an event to a topic. Kafka determines which partition the event should be written to, either through a key or a round‑robin distribution strategy. The broker that is the leader for that partition receives the event and appends it to the partition log.
Follower replicas copy the event from the leader so that multiple brokers contain the same data. Consumers that belong to a consumer group then read events from those partitions. Kafka assigns partitions across consumers in the group so processing can occur in parallel.
This interaction between producers, partitions, leaders, and consumer groups is what enables Kafka to scale horizontally while preserving ordering within partitions.
Kafka Architecture Example: End-to-End Event Pipeline
A practical way to understand Kafka architecture is to look at how it is commonly used inside a real event pipeline.
Imagine an ecommerce platform processing customer orders.
- The checkout service publishes an order_created event to the orders topic.
- Kafka writes the event to the leader partition on one broker.
- Follower replicas copy the event to other brokers for durability.
- Multiple consumer groups read the same event stream for different purposes.
For example:
- An inventory service updates product availability.
- A payment processing service confirms the transaction.
- A shipping service prepares fulfillment.
- An analytics pipeline captures the event for reporting and machine learning.
Because Kafka stores events in a durable log, each consumer group can process the same event independently without interfering with other consumers. This design allows organizations to expand systems over time by simply adding new consumers that subscribe to existing event streams.
Kafka vs Traditional Messaging Architecture
Kafka architecture differs significantly from traditional message broker designs.
Traditional messaging systems typically use queues where messages are delivered to consumers and then removed once processed. Kafka instead uses a distributed log. Messages remain stored for a configured retention period and can be replayed by consumers.
Key differences include:
- Messages are stored in an append-only distributed log rather than removed from queues after processing
- Consumers track offsets and can replay historical data for analytics, recovery, or reprocessing
- Partitioning distributes data across brokers instead of queue sharding models
- Sequential disk writes improve throughput compared with random I/O patterns used by many traditional messaging systems
These architectural choices make Kafka particularly well suited for streaming pipelines and large-scale event ingestion.
Kafka Architecture in Modern Data Platforms
Kafka architecture is commonly deployed as the central streaming layer within modern data platforms. Instead of connecting every system directly to every other system, Kafka acts as a central event backbone that distributes data across the organization.
A typical enterprise architecture might look like this:
Operational systems publish events into Kafka, including applications, databases using change data capture, and IoT devices. Stream processing frameworks then transform and enrich those events. Downstream consumers include analytics platforms, data warehouses, machine learning systems, and operational services.
In this model, Kafka becomes the system responsible for moving real-time data between many independent platforms. The architecture allows teams to add new consumers without modifying existing producers, which significantly reduces coupling between systems.
Common Kafka Architecture Pitfalls
Although Kafka architecture is powerful, many teams encounter challenges when operating large deployments.
- Partition Proliferation: Partitions enable scaling, but too many partitions can create operational overhead. Large numbers of partitions increase metadata load, rebalance times, and controller responsibilities.
- Consumer Group Rebalancing: When consumers join or leave a group, Kafka rebalances partitions across the group. Large consumer groups or frequent scaling events can trigger long rebalances that temporarily pause processing.
- Replication Lag: Follower replicas must stay synchronized with leaders. Under heavy load or network congestion, replication lag can grow, increasing the risk window during broker failures.
- Operational Complexity: Running Kafka clusters requires managing storage, monitoring replication health, tuning partition counts, and scaling infrastructure. These operational requirements often lead organizations to adopt supporting platforms or managed services.
Understanding these challenges helps architects design clusters that remain stable as workloads grow.
Kafka Architecture FAQ
What is Kafka architecture?
Kafka architecture is a distributed system for storing and distributing streams of event data. It uses clusters of brokers that store events in topics and partitions so producers can publish data and consumer groups can process that data independently.
How does Kafka architecture scale?
Kafka scales horizontally by distributing partitions across multiple brokers. As workloads grow, additional brokers can be added to the cluster, allowing partitions and consumer workloads to be distributed across more servers.
Is Kafka a message broker or an event streaming platform?
Kafka is typically described as an event streaming platform built around a distributed log. While it supports publish/subscribe communication, its architecture centers on storing event streams that consumers retrieve and process.
Why does Kafka use partitions?
Partitions allow Kafka to distribute event data across brokers and enable parallel processing. Each partition maintains ordered events while allowing multiple consumers in a consumer group to process different partitions simultaneously.
Key Takeaways
- Kafka runs as a distributed cluster of brokers that store and distribute event streams.
- Topics organize event data, while partitions allow the system to scale horizontally.
- Producers publish events and consumer groups process them in parallel.
- Replication ensures durability and allows brokers to fail without losing data.
- Kafka’s architecture is optimized for high-throughput streaming pipelines and large-scale event ingestion.
Final Thoughts on Kafka Architecture
Kafka architecture is built around a distributed log that allows massive volumes of events to be written, stored, and consumed across many independent systems. Brokers distribute data across clusters, partitions enable parallel processing, and replication protects against failures.
These design decisions allow Kafka to support large-scale streaming pipelines, real-time analytics platforms, and event-driven application architectures.
For architects and developers building modern distributed systems, understanding Kafka architecture provides the foundation needed to design scalable real-time data platforms.