The question “What are the patterns of event-driven architecture?” comes up a lot and might seem simple, but a quick review of the many answers offered up by well-meaning and well-informed experts exposes the fact that there’s more to it than you might think. Their lists vary in size, style, and substance, and the amount of overlap and gaps between them belies the fact that there’s no unanimous definition of what’s meant by a “pattern.”
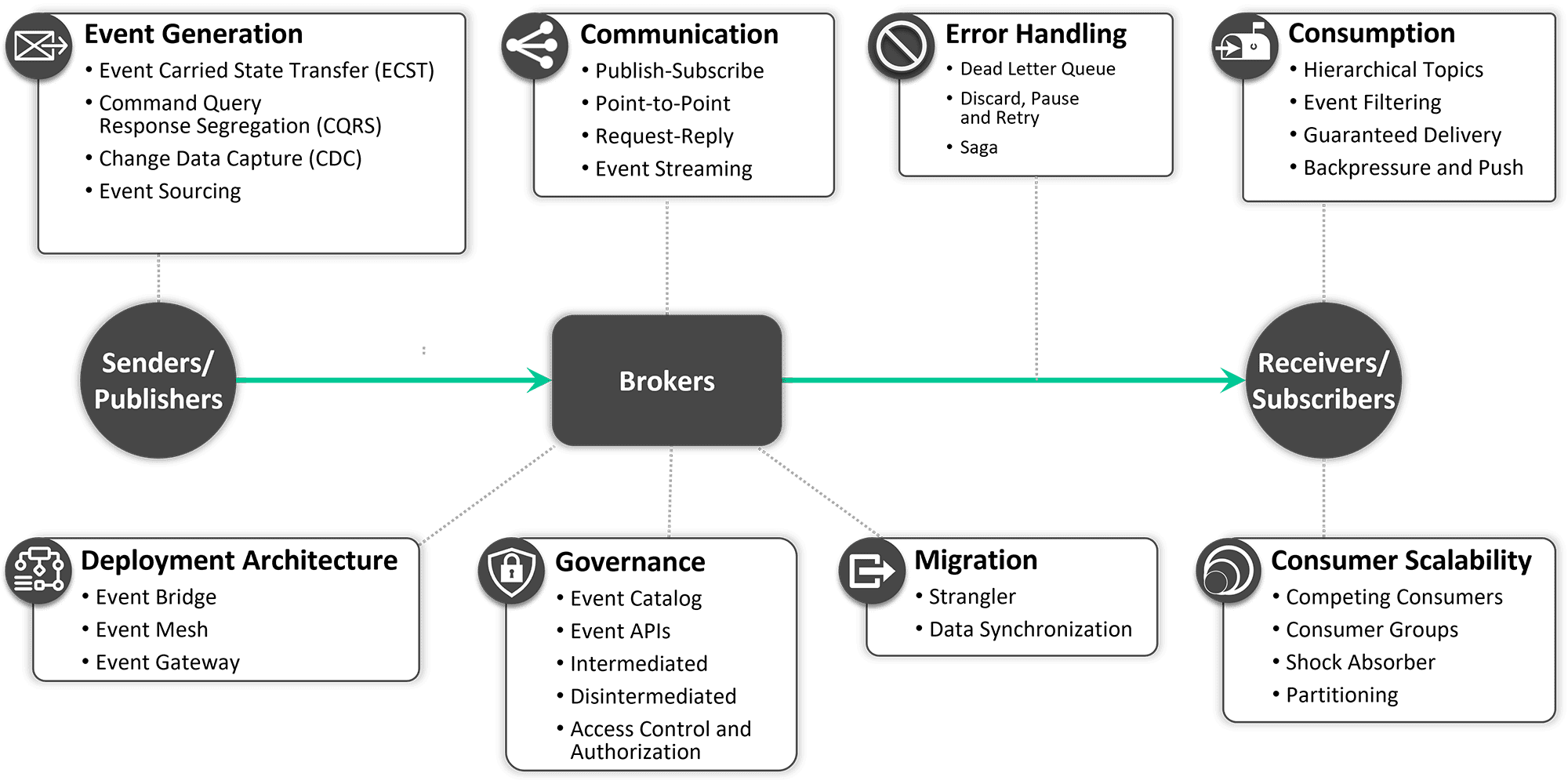
The key to breaking through the noise and arriving at a pretty-universally-acceptable definition of the patterns of event-driven architecture is to peel back the onion and consider different kinds of event-driven architecture patterns:
- Event Generation Patterns: ECST, CQRS, CDC, event sourcing
- Communication Patterns: point-to-point, publish/subscribe, request/reply, event streaming
- Consumption Patterns: hierarchical topics, event filtering, guaranteed delivery, backpressure and push, exclusive consumer
- Consumer Scalability: competing consumers, consumer groups, shock absorber, partitioning
- Deployment Architecture Patterns: event bridge, event mesh, event gateway
- Error Handling Patterns: dead letter queue, discard, pause and retry, saga
- Governance Patterns: event catalog, event APIs, intermediated, disintermediated, access control and authorization
- Migration Patterns: strangler, data synchronization
- References
With this post, you’ll learn about the taxonomy of event-driven architecture patterns and and be introduced to useful patterns from communication to governance. Not mutually exclusive, some applications and use cases can require combinations of patterns in different areas. Read more and discover some of the popular and important patterns in each of these categories.
Event Generation Patterns
Event generation patterns in event-driven architecture involve techniques and strategies for generating events that represent significant occurrences or changes within a system. These patterns define how events are identified, captured, and produced based on specific triggers or conditions. These patterns enable the detection and extraction of relevant information, ensuring that important events are generated and made available for consumption by other components or services within the event-driven ecosystem. By capturing and generating events, these patterns facilitate real-time responsiveness, data synchronization, and the propagation of relevant information throughout the system.
Event Carried State Transfer (ECST)
Event-carried state transfer (ECST) is an event-driven architecture pattern that utilizes events as a mechanism for state propagation, rather than relying on synchronous request/response protocols. This decouples services, improves scalability and reliability, and provides a mechanism for maintaining a consistent view of the system’s state.
By utilizing the ECST pattern, services can operate independently and scale more effectively. Each service can subscribe to the events that it is interested in and update its own local state accordingly. It also provides a mechanism for maintaining a consistent view of the system’s state. By propagating events to all interested parties, services can ensure that they have the most up-to-date view of the system’s state. This is especially important in highly distributed systems where it can be challenging to maintain a consistent view of the system’s state.
Learn More
- Event-driven design: The Value of Event Carried State Messages
(Mike Amundsen, Mulesoft blog, January 2021) - The Event-Carried State Transfer Pattern
(Oskar uit de Bos, ITNEXT, November 2021) - Event-Carried State Transfer: A Pattern for Distributed Data Management in Event-Driven Systems
(Michael Di Prisco, DEV Community, May 2023)
Command Query Response Segregation (CQRS)
Command query responsibility segregation (CQRS) is a pattern used in event-driven architecture that separates the processing of commands from the processing of queries. In this pattern, commands are used to modify the state of an application while queries are used to retrieve the state of the application. The separation allows for the creation of dedicated components optimized for each operation.
In the world of microservices, scaling can be accomplished by separating the service responsible for doing something (command) and the service responsible for answering queries. Typically, you have to answer many more queries than for an update or insert, so separating responsibilities this way makes scaling the query service easier.
CQRS provides many benefits to an application, including improved scalability, performance, and maintainability. By separating the read and write models, CQRS allows for independent scaling and optimization of each model. Additionally, the use of events to represent changes to the state of the application provides a clear audit trail and enables the creation of event-driven systems.
Learn More
- Command-Query Responsibility Segregation (CQRS)
(IBM Cloud Architecture Center) - Deep Dive into CQRS — A Great Microservices Pattern
(Kevin Vogel, Level Up Coding, April 2022) - Introduction to CQRS; Essential Concepts Every Developer Should Know
(Amanda Bennett, Microservice Geeks, February 2021)
Change Data Capture (CDC)
Change data capture (CDC) is a pattern used in event-driven architecture to capture and process changes made to a database. The CDC pattern is used to track changes to a source database and transform them into a format that can be easily consumed by downstream systems such as data warehouses, data lakes, and streaming applications.
CDC works by detecting changes made to the source database and publishing them as events. These events can be consumed by other systems, allowing them to keep their data in sync with the source database in real time. CDC can also be used to provide a history of changes made to a database, which can be useful for auditing and compliance purposes.
In event-driven architecture, CDC is often used in conjunction with other patterns such as event streaming and stream processing to build real-time data pipelines. CDC provides a way to capture and transform the data changes that occur in a database, while event streaming and stream processing provide mechanisms to process and analyze the data as it flows through the pipeline.
CDC captures individual data changes providing granular representation and is closely tied to the underlying database technology. However, if you want the changes to be captured in a transactional context, you can use the Transactional Outbox pattern.
Learn More
- Change Data Capture + Event-Driven Architecture
(Derek Comartin, CodeOpinion, June 2023) - What is Change Data Capture?
(RedHat, March 2021) - A Gentle Introduction to Event-driven Change Data Capture
(Dunith Dhanushka, Event-driven Utopia, February 2021) - Oracle GoldenGate Top 5 Announcements at Oracle CloudWorld 2024
(Jeff Pollock, Oracle, September 2024)
Event Sourcing
Event sourcing is a pattern used in event-driven architecture that involves capturing all changes to an application’s state as a sequence of events, rather than just the current state. This sequence of events is used to build and rebuild the state of the application, making it an essential pattern for systems that require auditability and replayability.
At any point in time, the current state of the application can be built by replaying all the events in the event store from the beginning of time. This allows the system to always have an up-to-date view of the application’s state and enables developers to easily diagnose and troubleshoot issues that may arise.
Event sourcing is often used in conjunction with the CQRS pattern described above, which separates the write and read operations of an application, enabling different views of the same data to be optimized for their specific use cases. By using CQRS, developers can optimize the write operations to efficiently generate events and update the event store, while simultaneously optimizing the read operations to efficiently query the data and provide real-time views of the data.
Learn More
- Event Sourcing Pattern
(Microsoft) - What (and Why) is Event Sourcing?
(Kevin Vogel, Level Up Coding, April 2022) - Event Sourcing
(IBM Cloud Architecture Center)
Communication Patterns
Communication patterns in event-driven architecture encompass various techniques and approaches for enabling communication and data exchange between different components and services within a distributed system. These patterns define how events are propagated, delivered, and consumed, ensuring reliable and efficient communication between event producers and consumers. They play a crucial role in establishing loose coupling, enabling real-time and asynchronous communication, supporting scalability, and facilitating the integration of diverse systems within an event-driven ecosystem.
When two applications want to exchange data, they wrap it in a message. However, messaging involves more than just sending bits on the wire. To make it effective, several factors must be considered. Firstly, the message’s intent must be clear, and there are three major types of messages:
- Command Messages are used to request or instruct a specific action to be taken by a recipient. They are typically sent from a sender to a specific receiver, specifying the intended operation to be carried out. Command messages are often used to initiate a business process or trigger a workflow or a specific behavior in a service or component. They are considered to be imperative in nature and carry a directive or command.
An example would be a command message sent to a payment service requesting it to process a payment transaction. - Document Messages are used to communicate data or information between different components or services. They typically carry a payload containing structured data, such as JSON or XML, that represents a document or a piece of information. Document messages are often used for data exchange and sharing, and they can be consumed by multiple subscribers or services.
An example would be a document message carrying customer data sent to an analytics system for further processing. - Event Messages represent an occurrence or state change in a system, also called as notifications. They are typically used to notify interested parties about something that has happened. Event messages are often published to a message broker, and interested subscribers or services can consume these events. They are important for enabling loose coupling and decoupling of components within an event-driven architecture.
An example would be an event message published when a new order is placed in an e-commerce system, notifying downstream systems such as inventory management, payment processing and shipping.
An Event Message can further be classified based on the amount of data carried.- Notification only: The event includes a business object key and maybe a link to retrieve data
- Notification + Metadata: Same as Notification, but carries additional metadata to indicate changes
- Notification + Data: Event includes all relevant data required to act (also called Event Carried State Transfer)
Secondly, the sender needs to have a strategy, such as consuming, sending a response on receipt, or acting when using a request-reply mode of interaction. Depending on the use case, the sender may also choose to ensure a guaranteed order of delivery and set an expiration date.
These are the key communication patterns used when building event-driven architecture:
Publish-Subscribe
Publish-subscribe is a communication pattern that decouples applications by having them publish messages to an intermediary broker rather than communicating directly with consumers (as in point-to-point). This approach introduces an asynchronous mode of communication between publishers and subscribers, offering increased scalability, improved reliability, and the ability to defer processing with the use of a queue on the broker.
In this sense, publishers and consumers do not have any knowledge of each other; they simply produce or receive the events. The event broker, which may take the form of middleware software, an appliance, or a SaaS deployed in any environment, facilitates and distributes events as they occur, pushing them to consumers that may be located in a variety of environments (such as on-premises or public/private clouds).
The publish-subscribe pattern is often used in event-driven architecture for building event-driven microservices architectures and real-time streaming. It can help decouple different parts of an application, enable flexible scaling, and support real-time processing of large volumes of data.
Learn More:
- What is the Publish-Subscribe Messaging Pattern?
(Sarah Diguer, Solace blog, January 2020) - Pub/Sub Messaging
(AWS) - 3 Message Exchange Patterns in Application Integration You Should Know About
(Olga Annenko, Elastic blog, October 2016)
Point-to-Point
If you need to deliver a message to a specific recipient, the publish-subscribe mode isn’t necessary. In such cases, the point-to-point message exchange pattern is used to deliver the message to a single recipient in what’s called a “one-to-one” exchange. It is also possible that several senders send messages to the same recipient, a “many-to-one” exchange. In these situations, the endpoint typically takes the form of a named queue. If several receivers are connected to the queue, only one of them will receive the message.
Learn More
- Point-to-point messaging
(IBM Cloud Architecture Center) - 3 Message Exchange Patterns in Application Integration You Should Know About
(Olga Annenko, Elastic blog, October 2016) - System Integration: Types, Approaches, and Implementation Steps
(AltexSoft blog, March 2021)
Request-Reply
While both publish-subscribe and point-to-point communication modes facilitate one-way communication, a request-reply pattern is necessary when your goal is specifically to get a response from the recipient. This pattern ensures that the consumer sends a response to each consumed message, with the implementation varying from the use of a return address to sending a response to a separate endpoint.
In essence, we are examining two distinct messaging operations: one where the requestor transmits a message using either a point-to-point (deliver) or publish-subscribe (broadcast) mode, and the other where the receiver replies to the request in a point-to-point manner directed to the sender. It is important to note that the reply exchange is always point-to-point, as the intent is solely to return the response to the requestor.
Learn More
- Request-Reply Messaging
(IBM Cloud Architecture Center) - 3 Message Exchange Patterns in Application Integration You Should Know About
(Olga Annenko, Elastic blog, October 2016) - Beyond Request-Response: Understanding the Event-Driven Architecture
(Abishek Kumar, Medium, January 2023)
Event Streaming
Event streaming is a communication pattern in event-driven architecture that allows for the continuous delivery of events to interested parties. It is often used in event-driven architecture to decouple applications and services and to enable real-time processing of events. In this pattern, data is continuously ingested from various sources and streamed in real-time, enabling the ability to build instant insights and take immediate actions.
The event streaming pattern enables the creation of highly responsive and real-time systems that can analyze and act on data as it arrives. This pattern is often used in applications that require real-time monitoring, such as fraud detection, predictive maintenance, and IoT systems.
Learn More
- What Is Event Streaming? Why Is It Growing in Popularity?
(Panndio blog, June 2021) - How Stream Processing Makes Your Event-Driven Architecture Even Better
(Jason Skowronski, DEV Community, December 2019) - Event-Streaming: An Additional Architectural Style to Supplement API Design
(James Higginbotham, Capital One Tech, April 2018)
Consumption Patterns
Consumption patterns in event-driven architecture encompass strategies and techniques for consuming and processing events generated within the system. These patterns define how events are received, filtered, and acted upon by event consumers. These patterns enable components and services to react to relevant events, trigger appropriate actions, update their internal state, and propagate new events if necessary. Consumption patterns facilitate decoupled and asynchronous processing, allowing components to respond to events in real-time, maintain data consistency, and orchestrate complex workflows based on received events.
Hierarchical Topics
A topic is a fundamental concept in event-driven architecture that allows events to be categorized and routed to interested consumers. However, the way topics are implemented varies between different event brokers.
Some brokers offer a flat topic structure, while others provide a hierarchical structure. Additionally, some brokers use partitioning to improve scalability and ensure related events are routed to the same partition. A hierarchical topic structure with wildcard subscriptions allows for more granular control over topic subscription and filtering, enabling consumers to receive only the events they are interested in.
It is important to evaluate the capabilities of your event broker before defining a topic structure to ensure it meets your needs for scalability, resilience, and flexibility.
Learn More
- Topic Hierarchy and Topic Architecture Best Practices
(Ken Barr, Solace blog, March 2020) - Topic Architecture Best Practices
(SAP) - MQTT Topics, Wildcards, & Best Practices
(HiveMQ blog, August 2019)
Event Filtering
How can a component avoid receiving uninteresting events? Event filtering is a pattern that allows consumers to specify a set of rules to determine which events they will receive based on the event metadata or payload. This pattern is closely related to stream querying, but it applies specifically when a consumer uses an expression to decide which events to receive. It is important to note that the filtering features of event brokers can vary considerably.
Subscription-based brokers require all consumers to define a filter that the broker uses to decide which events to send to the consumer. The filter rules usually apply only to message metadata. On the other hand, in log- and queue-oriented brokers, filtering may be implemented in client code or on the broker. When the broker performs filtering, events that are not wanted by a client are not transmitted, which saves on bandwidth, client memory, and CPU resources. However, with consumer-side filtering, the event is sent to the consumer, but the client discards the event rather than delivering it to the application code, resulting in performance and networking overheads.
Learn More
- Message Filter
(EnterpriseIntegrationPatterns.com) - Event-driven Architecture with PubSub
(Google Cloud) - Event Correlation
(Wikipedia)
Guaranteed Delivery
The “guaranteed delivery” pattern is a crucial concept in event-driven architecture that focuses on ensuring the reliable and consistent delivery of events. In event-driven architecture, events represent significant occurrences or state changes within a system and are asynchronously communicated to components or services interested in them.
In distributed systems, it is vital to guarantee that events reach their intended recipients reliably, even in the presence of failures, network issues, or disruptions. The Guaranteed Delivery pattern addresses this requirement by introducing mechanisms that prevent event loss or omission during transmission.
By persisting events, the system ensures they are durable and can be recovered in case of failures or disruptions. Acknowledgments provide feedback to the sender, confirming successful event delivery. Delivery retry mechanisms allow for the retransmission of events in case of failures, with an approach that can optionally increase the time between attempts. Idempotency ensures that processing the same event multiple times yields the same outcome as processing it once.
By adopting the Guaranteed Delivery pattern, the reliability, fault tolerance, and consistency of event processing are significantly enhanced. It ensures that critical events are not lost, enabling systems to maintain integrity and consistency even when faced with failures or disruptions.
Learn More
- Guaranteed Delivery
(EnterpriseIntegrationPatterns.com) - Message Delivery Semantics in Streaming Platforms | Baeldung
(Uzma Khan, Baeldung, December 2022) - How to Guarantee Delivery While Preventing Duplicates in your Event Mesh
(Tom Fairbairn, Solace blog December 2022)
Backpressure and Push
Backpressure and push is an event-driven architecture pattern that deals with managing the flow of data between systems or components with different processing speeds. It is designed to prevent data loss or degradation due to overload.
To avoid this problem, the backpressure and push pattern uses a mechanism where the receiver sends a signal back to the sender indicating its readiness to receive more data. This signal is called backpressure. When the sender receives this signal, it slows down the rate at which it generates and sends events, allowing the receiver to catch up. Once the receiver is ready to process more events, it sends another Backpressure signal to the sender, and the process continues. In some brokers, the broker offers a self-backpressure mechanism based on the configuration of max unacked + receive window size, relieving the receiver of the signaling responsibility.
The backpressure and push pattern helps to ensure smooth and efficient data flow between components by managing the rate of event processing based on the capacity of the receiving system.
Learn More
- Backpressure explained — the resisted flow of data through software
(Jay Phelps, Medium, January 2019) - Backpressure Pattern- Design Principle
(Aravind Govindaraj, C# Corner, May 2023) - Avoiding a Queue Backlog Disaster with Backpressure & Flow Control
(Derek Comartin, Code Opinion, June 2022)
Exclusive Consumer (HA)
The exclusive consumer pattern plays a crucial role in event-driven architectures, particularly in scenarios where the sequence and integrity of message processing are critical. This pattern ensures that while multiple consumers are set up for redundancy, only one consumer actively processes messages at any given time. This setup prevents message duplication and guarantees that each message is processed in its correct order. An essential feature of this pattern is its automatic failover mechanism, which allows a secondary consumer to seamlessly assume processing duties if the primary consumer fails, thus maintaining uninterrupted service. Although this pattern significantly boosts data integrity and system reliability, it relies on robust support from the underlying messaging broker to manage consumer readiness and handle seamless transfers effectively. This pattern offers an error-free, sequential data handling to ensure transactional accuracy and maintain system robustness.
Learn More
- RabbitMQ: Single Active Consumer for Streams
- ActiveMQ: Exclusive Consumer
- Asynchronous Messaging Patterns
Consumer Scalability Patterns
Scalability is a key concern for any enterprise system, and it becomes even more critical when events are flowing continuously through the system. Scalability patterns in event-driven architecture are techniques and best practices for building systems that can handle large volumes of events and scale efficiently to meet demand. These patterns address various aspects of scalability, such as distributing the workload across multiple nodes, handling spikes in traffic, and dynamically adjusting the resources to match the workload. By leveraging scalability patterns in event-driven architecture, organizations can build systems that are highly available, responsive, and resilient to failures.
Competing Consumers
Competing consumers is a scalability pattern in event-driven architecture that involves distributing the workload of processing events among multiple consumers to improve throughput and reduce processing time. In this pattern, multiple consumers or worker processes are used to process events from a shared event stream or queue in parallel. Each consumer listens to the same stream of events and processes only a subset of events, thus distributing the workload across multiple consumers.
This pattern is useful when dealing with high-volume event streams where a single consumer may not be able to keep up with the event rate or handle the processing workload efficiently. By using multiple consumers, the processing can be parallelized, allowing for better resource utilization and improved scalability.
Learn More
- Competing Consumers Pattern Explained
(Aravind Govindaraj, Event-driven Utopia, May 2023) - Competing Consumers Pattern
(First Decode) - Competing Consumers Pattern for Scalability
(Derek Comartin, Code Opinion, June 2021)
Consumer Groups
The consumer groups pattern is similar to the competing consumers pattern but with an added layer of abstraction. In this pattern, a group of consumers is created to receive messages from a single event stream or message queue. Each consumer in the group processes a subset of the events, and the events are load-balanced across the consumers in the group. The messaging system ensures that each event is processed by only one consumer in the group.
The benefit of using consumer groups is that they provide a level of abstraction that allows for greater flexibility and scalability. Consumers can be added or removed from the group as needed, without affecting the overall processing of the events. This pattern is commonly used in distributed systems where multiple services or applications need to consume the same event stream.
The actual consumption of messages can be based on a simple round-robin scheme or more sophisticated schemes like sticky load-balancing using a key/hash scheme.
Learn More
- Consumer Groups and Consumer Scaling in Solace PubSub+
(Aaron Lee, Solace blog, November 2020) - Kafka concepts and common patterns
(Malcolm, Beyond the Lines, June 2017) - What is a consumer group in Kafka? – DEV Community
(Dejan Maric, DEV Community, March 2020)
Shock Absorber
The shock absorber pattern is a common technique used in event-driven architecture to mitigate the effects of bursty events that can lead to service degradation or failures. The pattern involves introducing a buffer or a queue between the event source and the downstream services that consume the events.
By introducing this buffer, the pattern can smooth out the flow of events, ensuring that no service is overwhelmed by a sudden burst of events. This buffer can also help to decouple the event source from the downstream services, providing a layer of insulation that can help to protect against unexpected changes to the event source.
When using a queue as the buffer, the shock absorber pattern can provide additional benefits. The queue acts as a persistent storage mechanism, allowing events to be buffered even when downstream services are not immediately available. This can be particularly useful in cases where downstream services have their own bursty workloads and may not always be available to consume events.
Learn More
- Understanding Solace Endpoints: Message Queue Access Types for Consumers
(Leah Robert, Solace blog, April 2023) - How to Relieve Backpressure In Message-Based Systems (clearmeasure.com)
(Corey Keller, Clear Measure, June 2022)
Partitioning
Partitioning is a design pattern in event-driven architecture that helps to improve scalability, performance, and reliability by distributing events across multiple queue partitions. The main idea behind this pattern is to partition a single queue into multiple smaller queues, allowing for higher throughput and reduced latency by processing messages in parallel. Each partition can be processed independently, which can increase concurrency and parallelism, thereby increasing the overall processing speed of the event system.
It helps in handling bursts of events by dividing the workload among multiple consumers that can process events in parallel. By partitioning the queue, the workload can be distributed among different servers or processing units, improving the overall efficiency of the event processing system.
Partitioning is an important concept in event-driven architecture that allows for scaling consumers. However, the implementation varies between different event brokers depending on the use of a queue or file for persisting events.
Learn More
- How Partitioned Queues Enable Consumer Autoscaling in Microservices Environments
(Rob Tomkins, Solace blog, May 2023) - Solace Office Hours – Feb 2023 – Partitioned Queues – YouTube
(Aaron Lee and Rob Tomkins, Solace Office Hours, February 2023)
Deployment Architecture Patterns
Deployment Architecture Patterns in event-driven architecture refer to different strategies and configurations for deploying and organizing the brokers involved in an event-driven system. Deployment Architecture Patterns include patterns such as centralized event hub, decentralized event hubs, hybrid deployments, multi-region deployments, and cloud-native architectures. These patterns help ensure scalability, fault tolerance, performance, and resilience in an event-driven system. They address considerations such as data locality, network latency, data privacy, and system reliability, allowing for efficient and effective distribution and management of events across the deployment infrastructure.
Event Bridge
The event bridge pattern is a deployment architecture pattern commonly used in event-driven architecture. It involves the use of two interconnected brokers that enable applications and services to send events across the bridge connection. This is achieved through subscriptions set on the bridge, which determine whether an event is allowed to flow across.
By adopting this pattern, each application or service can have its dedicated event broker. These brokers can be interconnected in a peer-to-peer manner, forming an ad-hoc network of brokers. Additionally, a broker can be part of multiple event bridges.
This distributed architecture provides several benefits over traditional centralized broker architectures, such as greater scalability, flexibility, and fault tolerance. By distributing the event processing workload across multiple brokers, the system can handle higher volumes of events and scale more easily. The bridge can be configured to be uni-directional or bi-directional, depending on the needs of the system.
In this pattern, each application or service publishes events to its local broker, which then distributes the events to the other broker of the event bridge(s) configured with a subscription. Subscribers to the events can then consume the events from their local broker. This approach eliminates the need for a central broker, which can become a bottleneck in high-volume systems.
Learn More
- Bridging Solace Message VPNs | Solace
(Ken Overton, Solace Blog, February 2017)
Event Mesh
The event mesh pattern in event-driven architecture is a relatively new concept that involves creating a network of interconnected event brokers that allow events to be published and consumed across different systems and environments. This pattern aims to address the challenges of event-driven architecture at scale, including event routing, discovery, and delivery, by creating a mesh-like network of brokers that can handle these tasks efficiently and reliably.
The event mesh pattern is designed to enable event-driven communication across complex distributed systems, which typically consist of multiple applications, services, and data stores. By creating a mesh of interconnected event brokers, this pattern allows events to be published and consumed by any component in the system, regardless of its location or technology stack.
One of the key benefits of the event mesh pattern is its ability to provide a decentralized and flexible approach to event-driven communication. With an event mesh, event producers and consumers can be added or removed dynamically, and events can be routed to their destination based on various criteria, such as topic or content.
In addition to improving the scalability and flexibility of event-driven systems, the event mesh pattern can also enhance their reliability and resilience. By leveraging multiple brokers to handle event delivery and failover, the event mesh can provide high availability and fault tolerance, even in the face of network failures or component outages. The Event Mesh pattern represents a promising approach to designing and deploying event-driven architectures that can meet the complex and evolving needs of modern distributed systems.
Learn More
- How an Event Mesh Supports Digital Transformation
(Shawn McAllister, Solace blog, October 2018) - Event Mesh
(Solace web site) - What is an event mesh? (redhat.com)
(Red Hate web site, August 2021) - Event Mesh as an Architectural Pattern | Solace
(Bruno Baloi, Solace blog, April 2023)
Event Gateway
The event gateway pattern serves as a vital component in connecting and coordinating events between brokers within an event mesh or event bridge, extending its capabilities to edge brokers located outside the mesh. Acting as a gateway or entry point for events, it facilitates event routing, transformation, and delivery to the intended recipients on the edge, leveraging subscription settings configured on the gateway.
The event gateway pattern builds upon the benefits offered by the event mesh pattern, with a particular emphasis on connecting applications and systems situated at the edges of the network. It enables seamless communication between the central event mesh or bridge and the distributed edge brokers, ensuring that events can be efficiently propagated to the appropriate destinations.
Error Handling Patterns
Error handling patterns in event-driven architecture encompass a set of strategies and techniques for managing errors and exceptions that occur within an event-driven system. These patterns are designed to handle and recover from errors, ensuring the reliability and resilience of the system. They help address scenarios such as failed event processing, network issues, unavailable services, and data inconsistencies. By implementing these patterns, event-driven architecture systems can effectively handle errors, minimize disruptions, and maintain the integrity and stability of event-driven workflows and processes.
Dead Letter Queue
In event-driven architecture, the dead letter queue (DLQ) pattern is used to handle messages that cannot be successfully processed by the system. When a message fails to be processed, it is typically routed to a dead letter queue, where it is stored and can be inspected and possibly reprocessed at a later time.
The DLQ pattern is used to prevent messages from being lost or discarded if they fail to be processed due to errors or other issues. By routing failed messages to a DLQ, they can be reviewed and addressed, either by fixing the issue that caused the failure or by manually reprocessing the message. A broker can also route a message to DLQ when a message lost its deliverability status due to TTL expiry, exceeding the maximum redelivery limit, or permission issues.
Implementing a DLQ requires configuring the message broker or middleware to route failed messages to a separate queue or log. It is also important to have processes in place to monitor the DLQ and take action to address any issues that are identified.
Learn More
- Dead Letter Queue Pattern
(IBM Cloud Architecture Center) - Reliable Message Reprocessing with Redpanda: Dead Letter Queues
(Dunith Dhanuska, Redpanda blog, November 2022) - Dead Letter Channel
(EnterpriseIntegrationPatterns.com)
Discard, Pause and Retry
The “discard, pause, and retry” pattern is an error-handling pattern commonly used in event-driven architecture to handle message processing failures. In this pattern, when a message processing error occurs, the message can be handled in one of three ways:
- Discard: The message is simply discarded, and no further action is taken. This option is typically used for non-critical messages that can be safely ignored.
- Pause: The message is temporarily paused and held in a retry buffer until the issue causing the failure is resolved. The message can then be retried and processed again.
- Retry: The message is retried immediately or after a specified delay. If the message processing still fails after a set number of retries, the message is either discarded or paused.
This pattern provides a way to handle message processing errors in a flexible and fault-tolerant way. By discarding non-critical messages, pausing and retrying failed messages, or immediately retrying messages that cannot be discarded, this pattern ensures that messages are processed in a timely and reliable manner, even in the face of failures. Additionally, it provides a way to prioritize message processing, so that critical messages are processed first, while non-critical messages can be discarded or processed later.
Learn More
- Exceptions and Retry Policy in Kafka | by Victor Alekseev | Dev Genius
(Victor Alekseev, Dev Genius, February 2021) - Retry Mechanism and Delay Queues in Apache Kafka | by Naukri Engineering | Naukri Engineering | Medium
(Naukri Engineering, Medium, June 2019) - Learn About the Retry Pattern in 5 Minutes
(Jennifer Davis, DEV Community, August 2019)
Saga
The saga pattern is a pattern used in event-driven architecture to ensure consistent outcomes for an application or process. It is often used as an error-handling pattern because it can compensate for errors that occur in an event-driven or streaming application. A saga is a sequence of transactions or operations that must occur in the correct order to ensure a specific outcome.
The implementation of the saga pattern can be thought of as building your own transaction coordinator. You create a component that observes the transactions executing and, if it detects that something has gone wrong, it can start to execute compensation logic. The saga pattern ensures that any errors or failed transactions are handled gracefully, allowing the application to recover without any negative impact on the end-user experience.
By using the saga pattern in event-driven architecture, you can maintain data consistency and ensure that any transactions that occur are executed in the correct order. This helps to avoid race conditions, data inconsistencies, and other issues that can arise when working with distributed systems.
Learn More
- Sagas
(Chris Richardson, Microservices.io) - Understanding the Saga Pattern in Event-Driven Architecture
(Michael Di Prisco, DEV Community, May 2023) - Saga Pattern
(IBM Cloud Architecture Center)
Governance Patterns
Governance patterns in event-driven architecture are essential for establishing control over access, management, security and oversight of the event-driven system. These patterns focus on establishing guidelines, policies, and frameworks for governing various aspects of the event-driven architecture ecosystem. Governance Patterns include topics such as event naming conventions, versioning and compatibility, security and access control, monitoring and auditing, and documentation standards. By implementing Governance Patterns, organizations can promote consistency, standardization, and best practices across the event-driven system. These patterns help maintain system integrity, enhance collaboration among teams, enable effective event discovery and management, and support long-term maintainability and scalability of the event-driven architecture implementation.
Event Catalog
The event catalog pattern provides a centralized location for documenting business events, making them easier to consume. The pattern includes an event developer portal that offers self-service access to information and documentation for published events, similar to how an API Developer Portal works for RESTful APIs. Additionally, the pattern utilizes a common/shared event broker, allowing for easy consumption of business events. By bringing event documentation together in one place, the Event Catalog pattern enables developers to more easily discover and understand the events being published, ultimately leading to more effective event-driven applications.
By maintaining a central catalog of events, it becomes easier to manage the different events in the system, including adding new events, removing deprecated events, and updating existing events. This can be especially useful in large, complex systems where there are many different events being produced and consumed by different services. The event catalog should include a description of each event, including its payload and any associated metadata and a release state. The catalog can also include information about the producers and consumers of each event, as well as any dependencies or constraints that need to be considered when using the event.
Learn More
- Document Service Events with EventCatalog | by IcePanel
IcePanel, Medium, May 3) - How to create an Event Catalog? – Blog by Kalle Marjokorpi
(Kalle Marjokorpi, own blog, April 2023) - Catalog
(Solace documentation)
Event APIs
The event APIs pattern in event-driven architecture is a design pattern that treats events as first-class APIs. Instead of using traditional request-response APIs, the event APIs pattern uses events to communicate between services. In this pattern, services publish events that describe the state changes in the system. Other services can then subscribe to these events to stay informed about the changes.
The key benefit of this pattern is that it provides loosely coupled, asynchronous communication between services. Services do not need to know about each other’s APIs or implementation details, which makes it easier to evolve services independently. It also enables the decoupling of producers and consumers, allowing consumers to be added or removed without affecting the producers. Certain policies around versioning, data formats, documentation, data relationships and presentation managed through traditional API Management principles can be applied to Event APIs as well.
To implement the event APIs pattern, an event schema should be defined that describes the structure and metadata of the events. This schema serves as the contract between producers and consumers, defining the format of the events and their associated metadata. Once the schema is defined, it can be shared between the producers and consumers to ensure interoperability.
Learn More
- How to Harness and Expose the Business Value of Events with Event API Products
(Jonathan Schabowsky, Solace blog, August 2021) - How to Expose Events with Event API Products Using Event Portal 2.0
(Giulio Graziani, Solace Resource Library, November 2022)
Intermediated Governance
Intermediated governance refers to an architecture that has a component called a gateway that intercepts the traffic between a client and an API, and in the process applies governance rules (aka policies). Essentially the gateway hosts and manages API proxies and enforces policies on those proxies, i.e. before routing the traffic from the client to the required API, it will apply the necessary security and traffic shaping constraints.
This is rather simple when you’re talking about synchronous RESTful APIs, but complicated by the nature of event-driven architecture. Even though there will still be a gateway in the middle, as opposed to having just a client and an API, and needing to restrict access only to the client, you now have a producer and a consumer, and you need to restrict access to both. Another consideration for an event-driven API gateway is the need to support multiple protocols. Producers and consumers will leverage the same transport protocol (Solace/Kafka/JMS/MQTT/AMQP etc.), but since they’re not all the same, the gateway needs to know which policies apply to which protocol.
A gateway-based architecture is ideal for scenarios in which cost and latency aren’t key considerations, and gateway-based systems are easier to manage since they do not incur or require additional development costs.
Learn More
- Governance in the World of Event-Driven APIs
(Bruno Baloi, Solace blog, May 2023)
Disintermediated Governance
You can also implement governance of event-driven APIs without a gateway. You still need a “manager” to handle the definition of policies and their assignment to various channels, but may not need a gateway if producers and consumer can access the API manager to download the policies associated with the channels they are connecting to, and have the ability to enforce those policies locally.
In this instance, you are essentially delegating policy enforcement to producers and consumers. For instance, when a developer generates the code scaffolding for a given AsyncAPI, they would have at their disposal a “Governance SDK” or library they could incorporate into their implementation.
This pattern achieves the same type of separation of concerns, but enforcement will be done by the clients (producers/consumers) not a gateway. The advantage is that there’s less operational impact on the infrastructure, as there are no gateways to deploy and provision, so less infrastructure overhead and cost, and that there’s no latency impact on the data flow. The downside of the direct governance model is that it puts the onus on the developers to incorporate governance into their applications and microservices.
Learn More
- Governance in the World of Event-Driven APIs
(Bruno Baloi, Solace blog, May 2023)
Access Control and Authorization
The Access Control and Authorization pattern focuses on controlling and managing access to resources in a system, including events and event-driven components, based on defined policies and permissions. This pattern ensures that only authorized entities have the necessary privileges to publish or consume events and perform specific actions within the event-driven architecture.
Implementation of access control and authorization could use Role-based Access Control (RBAC) or User-based Access Control policies to ensure that the access to the event-driven systems is secure and adhere to proper access control practices. This pattern helps prevent unauthorized access, protects sensitive information, and maintains the integrity and confidentiality of events within the event-driven architecture.
Learn More
- Architectural considerations for event-driven microservices-based systems – IBM Developer
(Tanmay Ambre, IBM Developer Resources, July 2020) - Event-Driven Architecture & the Security Implications
(Sterling Davis, Trend Micro blog, June 2023) - Authentication & Authorization in Microservices Architecture
(Tzachi Strugo , DEV Community, February 2021)
Migration Patterns
Migration patterns in event-driven architecture refer to a set of strategies and techniques for transitioning from an existing implementation – a monolith or an event-driven system to another event-driven system or upgrading the existing system while minimizing disruptions and ensuring a smooth migration process. These patterns address challenges such as data migration, schema evolution, backward compatibility, and the gradual adoption of new components or technologies. They help organizations navigate the complexities of migrating to event-driven systems, ensuring continuity, preserving data integrity, and enabling a seamless transition to the new or upgraded architecture.
Strangler
The strangler pattern is a migration pattern used to incrementally transition from a monolithic application to a microservices-based architecture in a controlled and gradual manner. This pattern involves identifying cohesive areas of functionality within the monolith, extracting them into independent services, and replacing the monolithic functionality with calls to the new services. Over time, the monolith is “strangled” as more and more functionality is migrated to the new services until the monolith is fully decommissioned.
In the context of event-driven architecture, the strangler pattern can be used to extract event-driven functionality from a monolithic application and migrate it to a distributed, event-driven microservices architecture. This involves identifying discrete event processing areas within the monolith, extracting them into independent event-driven services, and gradually replacing the monolithic event processing with calls to the new services.
The strangler pattern can be effective in addressing the challenges of large, complex monolithic applications that have grown unwieldy over time. It allows teams to break down large, tightly coupled systems into smaller, more manageable pieces that are easier to develop, test, deploy, and maintain. By gradually replacing functionality with new services, the pattern enables teams to migrate at their own pace, minimizing risk and ensuring that critical business functionality is not disrupted during the transition.
Learn More
- Pattern: Strangler Application
(Chris Richardson, Microservices.io) - Monolith to Microservices using Strangler Pattern
(Samir Behara, own blog, September 2018) - Strangler Pattern
(IBM Cloud Architecture Center)
Data Synchronization
The Data Synchronization migration pattern is used in event-driven architecture to ensure the consistent transfer and synchronization of data between different systems or components during the migration process. This serves the need to maintain data integrity and consistency while transitioning from one event-driven system or other software systems like database, mainframe, etc. to event-driven architecture.
This pattern has varieties of tools for use depending on the type of source system – a CDC or replication would work for a database source system, a connector/adapter in the case of legacy systems such as a mainframe, and an event replay if the source system is another event-driven system.
Learn More
- What Is, Why We Need, and How to Do Data Synchronization – DZone
(Ramindu De Silva, DZone, April 2020) - An Illustrated Guide to CQRS Data Patterns
(Bob Reselman, RedHat, March 2021)
References
- Patterns for Distributed Systems
- Cloud Design Patterns
- Event-driven Architecture Patterns
- Enterprise Integration – Messaging Patterns
- Enterprise Integration Patterns with WSO2 ESB
- Patterns in EDA
- Java Design Patterns
- A pattern language for microservices
- 6 Event-Driven Architecture Patterns
- Event-driven Solution
- Event-driven architecture
- EDA VISUALS – Small bite sized visuals about event-driven architectures
- Event-driven architecture for microservices
- The Complete Guide to Event-Driven Architecture
- My TOP Patterns for Event Driven Architecture
- Event Driven Microservices Architecture Patterns and Examples | HPE Developer Portal