Understanding Guaranteed Message Publish Window Sizes and Acknowledgments
One of the main advantages of Guaranteed Messaging (a.k.a. Persistent Messaging or store-and-forward messaging), is

When you’re designing an event-driven system, you need to decide what guarantees should be made that a given event will be delivered, and in what circumstances. For example, suppose a consumer is offline – should the event be saved and delivered later? What if a consumer can’t keep up with the messages being sent to it – how many system resources should you spend to store them until they can be delivered? And what should happen when those resources are exhausted?
When you decide what should happen in these cases, you’re setting the level of delivery guarantee. If the event must always be delivered to a consumer, you must accept that the event may be redelivered. In some cases, this introduces the need to guarantee delivery while also making sure messages aren’t delivered more than once, which can be tricky.

There are several ways to do so, each with drawbacks:
The only infallible way to prevent duplicate delivery is to use universally unique identifiers created by the event producer to implement idempotent processing i.e., ensure that that an action has no additional effect if it is called more than once with the same input parameters.
There are essentially 3 types of delivery guarantees:
I’ll explain the first two, and then introduce (and warn you about) “once only.”
Imagine your stream of events are the clickstream data from your e-commerce website. You’re running analytics to determine user behavior, optimize page layout etc. What should happen if the analytics system is offline? What about if the analytics engine can’t keep up?
You probably don’t want to wait until analytics is brought back on-line – it’s possible the pages have been updated in the meantime, making the data is stale. It would also probably be very expensive to store all that data. In short, you don’t need to persist this data.
What you want here is an example of the at-most-once delivery guarantee. If the receiver is able to accept the data, deliver it. Otherwise, the data could be stale, or it could be uneconomical to store it, or both, so it shouldn’t be delivered.
Simplified: Try to deliver it once, but if that fails, give up.
The MQTT standard has the concept of QoS 0, which corresponds to at-most-once. The Solace PubSub+ broker has the concept of the DIRECT delivery. RabbitMQ and Tibco EMS have in-memory queues which is kind of a hybrid of at-most-once and at-least-once, depending on the failure mechanism.
Now imagine the orders coming in from your e-commerce website. Even if your ordering system is offline or slow, you definitely want to make sure they are delivered, otherwise you lose orders and money, and annoy your customers.
That means you need to store these orders so that when your ordering system comes back on-line or catches up, no orders are lost, i.e., you need to make sure every order is delivered at least once.
This implies the need to persist the events – volatile RAM based storage will not suffice. You will probably also want to ensure the failure of one event broker will not result in lost data, introducing the need for high availability clustering of the brokers.
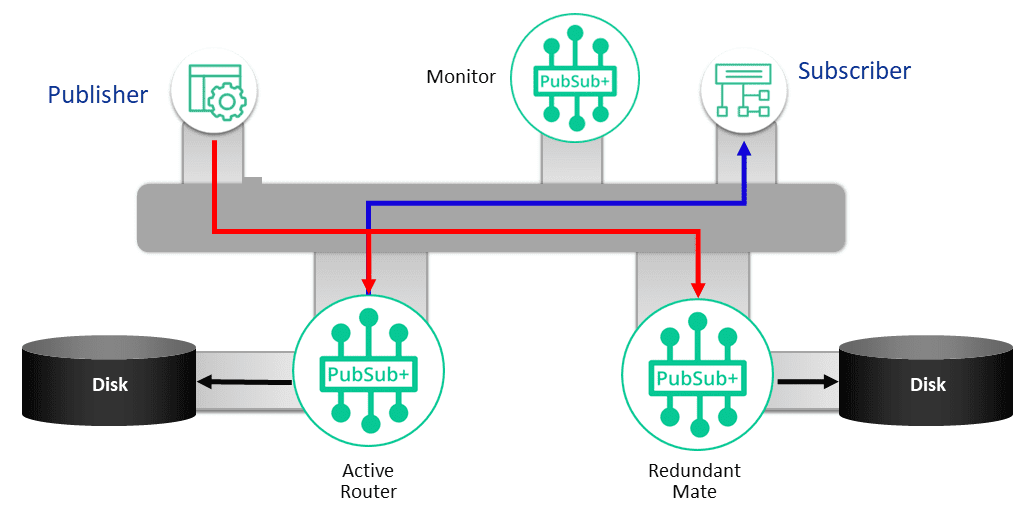
For this you can use MQTT QoS 1, Solace “guaranteed” delivery, and persistent queues with RabbitMQ or EMS.
Apache Kafka attempts to persist all data, with varying degrees of guarantee over whether data makes it to disk before a Kafka broker fails or whether the data has been replicated to another broker. It’s a complicated topic that I won’t even try to cover here.
With at-least-once delivery, there is a wrinkle: To ensure that your receiver has got the event and processed it, you have to use an acknowledgement mechanism. The receiver tells the broker that it has finished with the event, and to do this it sends an acknowledgement. It’s like signing for a package so the sender has proof it has been received.

Suppose an application receives an event, successfully processes it, and starts to send the acknowledgement, but fails to do so? (Example: they got the package, but didn’t finish signing the delivery slip.)
Or suppose they send the acknowledgement, but the broker fails before it receives and forwards it? (Example: the courier going bankrupt before getting the signed delivery slip to you.)
In either case, the message has been sent but no acknowledgement has been received.
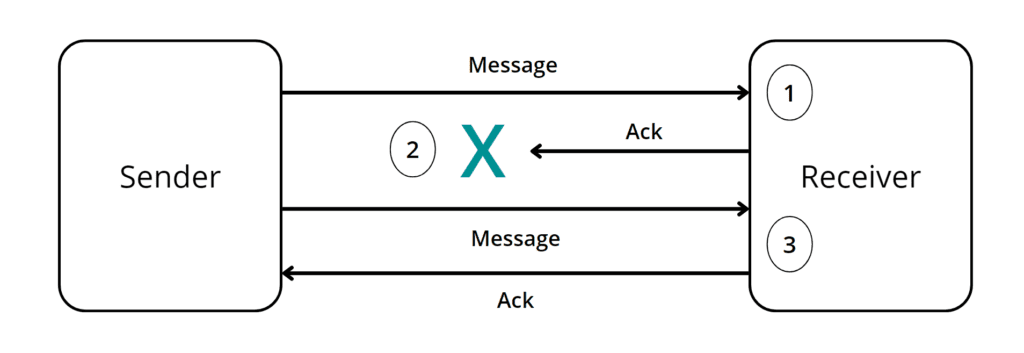 So you have a decision to make. With at-least-once delivery, you have decided that you must be certain the receiver gets the event, so you must re-send (redeliver) to guarantee the receiver gets the message at-least-once.
So you have a decision to make. With at-least-once delivery, you have decided that you must be certain the receiver gets the event, so you must re-send (redeliver) to guarantee the receiver gets the message at-least-once.
You have to deal with this redelivery, though, or you might get duplicates.
Some brokers, such as Solace PubSub+ Event Broker, help out by telling the consumer how many times the event has been delivered. The receiver can then take extra care during event processing. However, it isn’t always possible to ensure that the redelivery count is correct: a good example is during a DR switch over.

It’s almost impossible for a broker to be able to guarantee that the redelivery count is correct in all circumstances, so it should be used as an aid to event processing but not relied upon to detect duplicates. Use it to log that there’s been a problem with a message, for instance.
What if I cannot accept duplicates under any circumstances? For instance, for a payment?
A common way of ensuring an event cannot be duplicated is to use sequence numbers: the producer of the event inserts a globally unique sequence number into the event, so that any consumer of the event can tell if the event has been seen before.
This technique is used almost universally – it’s how TCP session ordering and de-duplication is performed.
On the consuming side, this is almost fool proof and reasonably easy to deal with. The problem is on the producer side: how do you create a globally unique sequence number?
Idempotency means that if a duplicate of the event arrives, it has no effect. This turns the problem on its head: rather than worrying about how to prevent a duplicate arriving, you simply ensure that if one does it has no effect.
For instance, let’s say I want to change my order for Finest Bone Apple Tea from 15 to 20. I could send a “+5” event, and that’s how market data systems tend to work. If I get a redelivery, though, I’ll end up with a total of 25 – it isn’t idempotent. I could instead send the total order I want – 20. Now if I get multiple redeliveries, only the first has an effect – it’s idempotent.
But only up to a point. Supposing I have events: Bone Apple Tea=15, then later Bone Apple Tea=20. All is good… but suppose I get both then Bone Apple Tea=15 is redelivered? If event ordering is guaranteed, there’s no problem, but if you can’t guarantee ordering, this won’t work.
Because of this problem, for most cases idempotency relies on sequence numbers, unique identifiers, unique keys, idempotency keys – they are all, in effect, the same thing.
Some event-based systems promise once-only delivery. MQTT sort of promises it with QoS2, and Kafka offers the same with Kafka transactions.
But there’s a problem: once-only delivery is actually impossible. It’s a well know problem in computer science called the “Two Generals Problem,” which poses the challenge of two generals of the same army trying to coordinate an attack when they can only communicate via messengers who travel through enemy territory so might be captured. If you’re not familiar with the concept, I suggest you watch Tom Scott’s excellent explanation on YouTube.
MQTT QoS 2’s solution relies on multiple acknowledgements, so while it does reduce the chances of redelivery it doesn’t solve the problem. A more detailed discussion of this can be found in Amelia Dalton’s excellent explanation in EE Journal.
Kafka’s exactly-once delivery applies to Kafka streams and so is local in scope. Kafka does have transactional producers, but these rely on user specified ids. The problem with this is you have to “..make sure the transaction id is distinct for each producer..” To be absolutely sure of this, you’d end up implementing a global UUID.
So far I’ve limited the discussion to duplicates sent between the event broker and a consumer. What about the producer side, though, i.e., how do you ensure that a failure on the producer side doesn’t result in the producer sending the same event twice?
You have to make sure you have a sequence number/idempotency key that can be generated in a consistent way, so that when the producer re-starts it will create the same key for the same events. With that done all you need to do is check what the last successfully sent event was.
Fortunately, some event brokers have a means of telling you what the last successfully sent event was. PubSub+ Event Broker, for instance, has the concept of a Last Value Queue. This is a queue that stores only the last successfully published event. On publisher re-start, you simply peek the value in this queue and extract the idempotency key. You can now move to the correct place in the event stream and start publishing from there, knowing you have not published any duplicates.
I hope I’ve helped you understand the limitations associated with various means of ensuring delivery. Some key points to take away: it’s impossible to guarantee a redelivery count is always correct in any system at scale. Don’t rely on re-delivery counts, or on event broker-generated sequence numbers as the basis for idempotency keys. And in any system at scale, you will need event producers to create their own idempotency keys.
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.


