I originally wrote this post as an internal technical note for my colleagues in the field: sales engineers, professional services consultants, trainers, new joiners, etc. Many people, both Solace and customers, have a difficult time understanding the nuances between “direct” messages and “non-persistent” messages in Solace. Or how exactly “non-persistent” is defined and implemented in the PubSub+ broker and APIs. I know I sure did! And this is especially true of anybody learning about Solace with previous JMS background (e.g. Tibco EMS, IBM MQ, etc.). It doesn’t help that the term “non-persistent” has a generally well-defined meaning in the industry to mean temporary or in-memory-only for messages.
Much of the content of this post can be found scattered throughout our documentation and tutorials, although some it I learned through experimentation and trial-and-error, and I thought I would post this publicly to make a one-stop-shop for clearing things up.
This includes information for developers using our APIs, as well as for admin/ops managing the brokers and assumes you have a decent understanding of Solace technology and terminology.
NOTE: all references below to JMS are JMS 1.1 as currently implemented by our Solace JMS API. It does not necessarily refer to JMS 2.0 (e.g. AMQP JMS 2.0 API).
Before we begin…
In Solace PubSub+ event brokers, there is no concept of an “in-memory” queue, or a RAM-only queue. Every message that lands on a Solace queue (or topic endpoint) gets written to non-volatile storage – either a disk, or the ADB in the hardware appliance. As such, every message in a queue will survive a broker failover or restart. This point will become important later.
Do Not Publish Non-Persistent in Non-JMS APIs
Unless you are using a JMS API, do not publish a message as “non-persistent”. When publishing a message with most of the Solace SMF APIs, you can change the message’s delivery mode. Always publish “direct”, or “persistent” (aka “guaranteed”) delivery mode if using the C API (CCSMP), JCSMP Java API, .NET C# API (CSCSMP), JavaScript or NodeJS APIs.
In fact, most of our API documentation specifically says that non-persistent is reserved only for JMS publishers.
JCSMP: https://docs.solace.com/API-Developer-Online-Ref-Documentation/java/com/solacesystems/jcsmp/DeliveryMode.html#NON_PERSISTENT
JavaScript: https://docs.solace.com/API-Developer-Online-Ref-Documentation/js/solace.MessageDeliveryModeType.html#NON_PERSISTENT
Note that for the new NextGen APIs (Java, Python, Go) that the ability to publish a message as non-persistent has been removed/hidden.
Promoted Direct Messages Become Non-Persistent
If publishing direct messages to a topic that matches a subscription on a queue (or topic endpoint), the messages are promoted into that queue as non-persistent; that is, the messages’ quality-of-service improves once it reaches the broker and gets spooled (stored) in a guaranteed endpoint. From this point on, the message is now fully guaranteed, and the consumer of the enqueued message will have to acknowledge the message off the queue when it is done processing it. That is, a message received as non-persistent has the exact same delivery guarantees from the broker-to-consumer as a persistent message.
Understanding Solace Endpoints: Queues vs. Topic Endpoints
From the consumer’s perspective, when receiving the message, it can see if promotion has occurred as it will say the delivery mode is non-persistent.
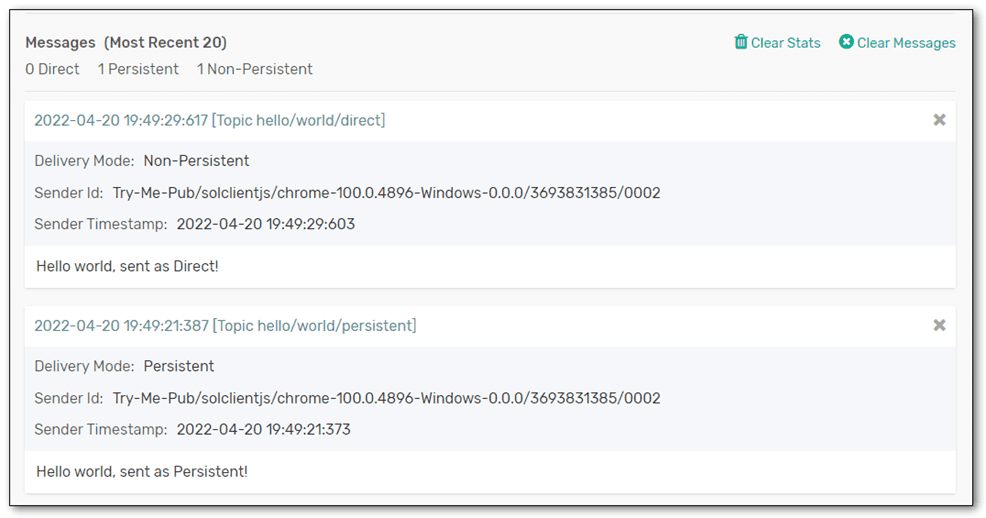
Fig 1: Try Me test consumer, receiving messages from a queue subscribed to hello/>
Unintentional Promotion?
This is actually very useful in a non-JMS environment to infer that message promotion is occurring, intentionally or otherwise. If you see queue consumers receiving non-persistent messages, or are looking at the message VPN stats or client stats and see that there are a lot of non-persistent messages being sent (by the router), then you can be pretty sure promotion is occurring somewhere.

Fig 2: Message stats for the broker, shown via CLI
This is also true for VPN bridges, if the bridge is configured for guaranteed messaging (with a bridge queue and subscriptions), and direct messages published in the remote message VPN are matching those subscriptions, the messages will be promoted into the bridge queue and then sent across as non-persistent.
It should be noted that promotion is not necessarily a bad thing, and that there are a number of interesting use-cases that depend on it. For example, a low-latency trading platform uses direct messages between apps for the lowest latency, but a queue with matching topic subscriptions might also attract those messages and buffer them to be sent to analytics or auditing applications. However, if you are building an application and want to ensure end-to-end publisher-to-subscriber guarantees against loss, then the publisher must send as persistent, and promotion is something to watch for.
Solace JMS API: Non-Persistent Publishing Can Have Different Transports
Messages published in Solace JMS as Persistent are always sent using guaranteed transport. In the JMS 1.1 spec, it specifies that the send() call in the API must block until the message is successfully acknowledged by the broker, or an exception is thrown.
But messages published as non-persistent can be sent using either direct transport or guaranteed transport. This is configurable in the Connection Factory (transport-properties → direct-transport → true/false).

Fig 3: Configuring a JNDI Connection Factory in PubSub+ Manager
Generally, unless building some very low-latency applications with JMS, it is almost always preferred to use guaranteed transport for non-persistent messages in JMS (i.e. direct-transport == false). Using guaranteed transport provides some nice features/capabilities for non-persistent messages. More on this later.
For more on publishing and consuming direct messages, visit: https://docs.solace.com/Solace-JMS-API/Direct-Transport-Behavior.htm
A Note on JMS Session Transactions
If you need to using transactions in your JMS publisher app, then you must have direct-transport turned to false. This is because the JMS spec allows both persistent and non-persistent messages in a transaction, and the Solace router needs to buffer all the messages sent until the commit() is called. If these were published as direct, the router would not buffer them and will send them immediately and be unable to roll them back.
The publisher will get an API error if your Connection Factory is configured for direct-transport and trying to do transactions.
Direct Transport
This is the choice for highest throughput, lowest latency, etc. If you want the highest performance and don’t need transactions, then you could use direct transport. Note that message loss can/will occur during network flaps (either publisher or subscriber temporarily disconnecting), and broker HA failovers or restarts as direct messages are in-memory only.
Guaranteed Transport
This is probably one of the more confusing things I try to explain to “other JMS” people when doing training or running a proof-of-concept feature evaluation: you can configure your Connection Factory to allow JMS published non-persistent messages to be sent using guaranteed transport. What does that mean?
JMS 1.1 does not have the concept of asynchronous acknowledgements for published messages (this has changed in JMS 2.0, which allows streaming Persistent publishing). When publishing a persistent message, the JMS spec states that the send() call either succeeds (which indicates the message has been persisted on the broker), or throws an exception (which indicates some delivery issue, such as a network disconnect, queue full, queue doesn’t exist, topic not subscribed to, etc.).
For non-persistent messages, there is no such requirement. When publishing non-persistent messages in JMS, the send() call will (should) return successfully even if there’s a problem with delivery on the broker. So because you’re publishing messages as non-persistent, if there’s a problem with delivery/storage on the broker, the spec says it can’t tell you (the publisher).
NOTE: Tibco EMS has an extension called “reliable” delivery mode which has the performance advantages of in-memory non-persistent messaging, but the API send() call will block on the acknowledgement from the broker.
There are some other advantages (besides transactions) for using guaranteed transport for non-persistent messages. If there is a network flap/outage, or an HA failover, and the publisher disconnects and reconnects without losing state (i.e. it didn’t crash), then the API and broker will actually re-establish the guaranteed flow and retransmit any messages that were in-flight and lost during the network disconnect.
Discarded Messages
If the queue is full or there is a publish ACL preventing the broker from accepting the message, then messages published as non-persistent will be discarded by the router and the sending application won’t know about it. The send() call will return successfully and not throw an exception. So, it’s possible to lose messages in this way.
The JMS API allows you to specify an exception listener on a connection. Through this, a publishing application could be made to know that something has gone wrong, but it would be unable to correlate exactly which message had the issue.
If you wanted to get fancy, maybe you could store published messages in a length-bounded linked list (length = 256), and if you ever received an exception, you’d know that one of those last messages had an issue.
If you wanted to get really fancy, one level of the topic hierarchy could be a published message UID, and then the publisher could correlate. But this involves parsing the free-text output of the exception, which is not ideal.
So if you use guaranteed transport for your non-persistent messages, the API will automatically resend messages during connection flaps and HA failovers (as long as your reconnects are long enough) and you won’t lose them. But it’s possible to lose messages due to misconfigurations, such as queue full, publisher ACL, etc.
JMS Publishers Have Two Ingress Flows (typically)
A flow in Solace is like a virtual pipe inside your TCP connection to the broker, and is used for sending guaranteed messages. Flows have additional flow control logic (window size) and acknowledgements on top of the standard SMF protocol. Ingress flows are created automatically when a client application connects to the broker; egress flows are created when a client binds/connects to a queue or topic endpoint. On the broker, you can see the flows in the client’s details, and total number in the message spool details.
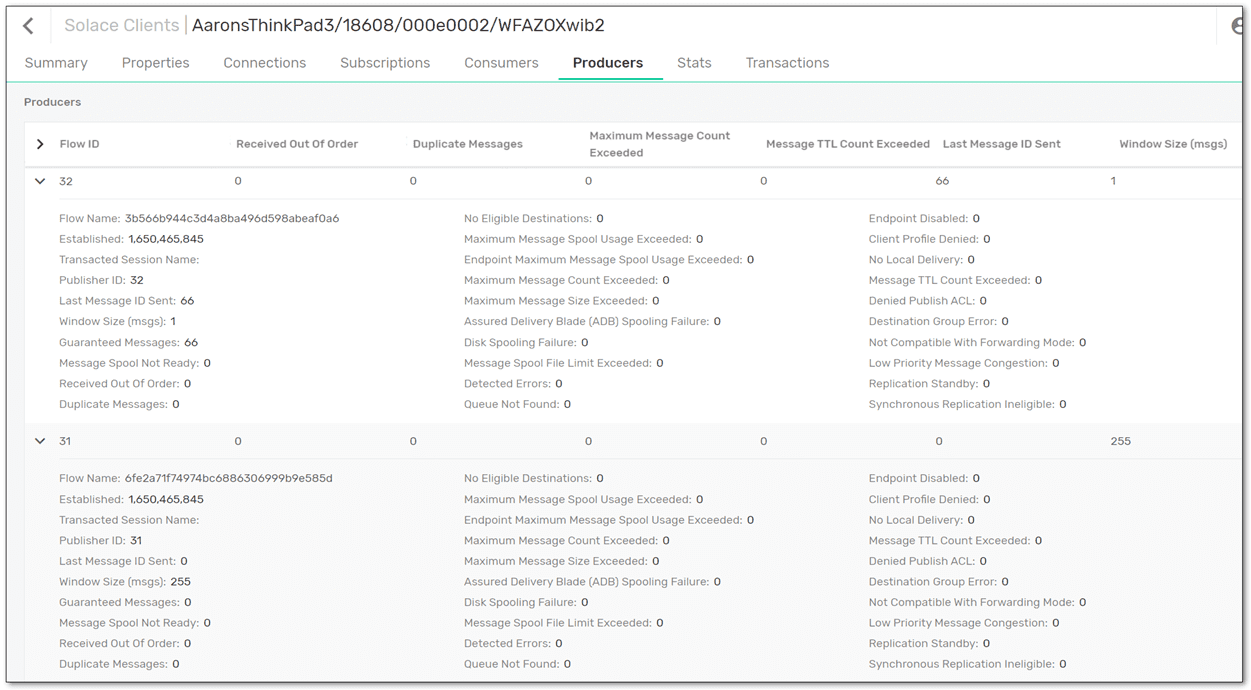
Fig 4: A JMS client’s Ingress Flows, called “Producers” in PubSub+ Manager
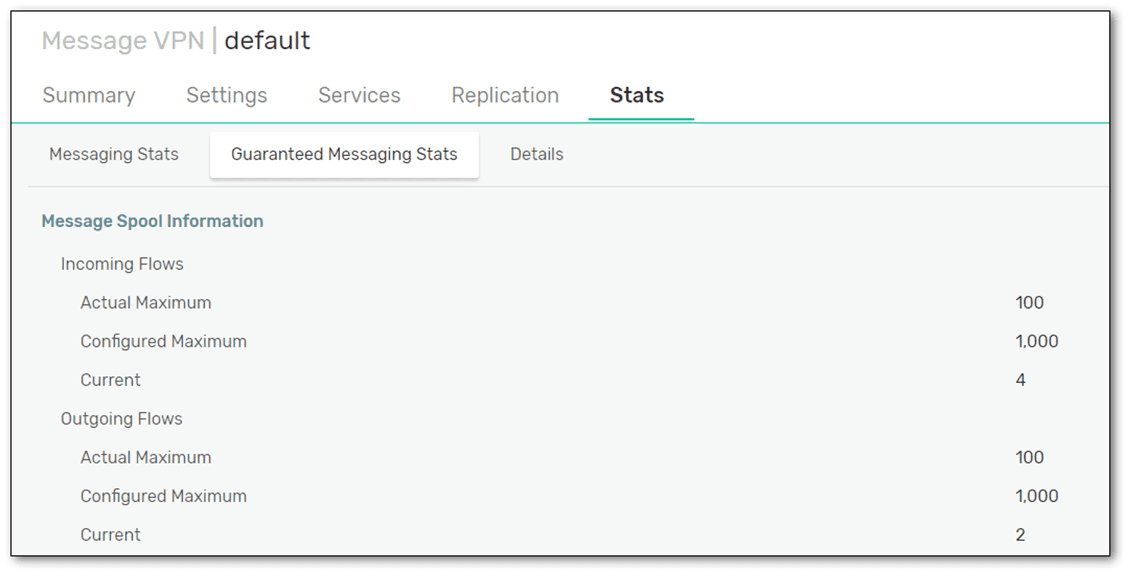
Fig 5: Message Spool stats for a Message VPN showing current number of Flows
When connecting a JMS client to Solace, two ingress flows will automatically be created by the API (that is, if the appropriate pre-conditions are there: direct-transport == false, the broker supports AD, client-profile has guaranteed message send enabled, etc.). One will have an AD Window of size 1, one will have an AD window of size (usually) 255… as determined by your Connection Factory setting: “send-ad-window-size”.
The ingress flow of size 1 will be used for persistent messages. Since the API call is blocking on a per-message basis, this aligns nicely with our AD window capability… setting the window size to be 1 means that only message can be in-flight at a time. The ingress flow of size 255 (or whatever) will be used for non-persistent messages.
Since JMS allows multi-threading within a connection, and you can publish persistent messages on any thread, our JMS API allows for this by opening additional ingress flows for every publishing thread.
When I was doing testing with Tibco BusinessWorks at Citi using Solace JMS, and a single JVM had 32 threads configured for parallelization, when the BW engine connected to Solace and started publishing, 32 ingress flows of AD Window size 1 would be opened by our API for that one connection. Only a single Ingress Flow of size 255 was opened for Non-Persistent messages, for use by any thread. You can see details of a client’s Flow by CLI command: show <client> message-spool-stats.
This is one reason why Solace is increasing the limits on # of ingress flows per appliance… to support multi-threaded JMS publishing applications.
Once on a Queue (or TE), the Message is Guaranteed
Solace has no concept of memory-only queues* like RabbitMQ or Tibco EMS. Once a message lands on a queue, published as either direct, non-persistent over direct, or persistent, attracted by either a topic subscription or publishing directly to the queue name or network topic, the message is guaranteed and cannot be lost due to power outages or whatever. From a router -> consumer perspective, persistent and non-persistent messages are handled the exact same way.
This also means that for a JMS queue consumer to connect and bind to a non-temporary queue, an actual Solace queue must exist. Therefore, Solace cannot support a completely in-memory message flow using queue producers and queue consumers. That would have to be done using topic consumers.
* There is (of course) a little-known exception to this… if connecting to a broker without AD capability (i.e. appliance with no ADB), and a JMS consumer creates and binds to a temporary queue, the API fakes this by creating topic subscription. Messages on that would be lost in the event of a disconnect.
Conclusion
I hope now you have a better understanding of the nuances between “direct” messages and “non-persistent” messages in Solace. If you’d like more information on Solace delivery modes and Solace endpoints, check out my colleague Leah’s blog posts:
- Understanding Solace Delivery Modes: Promotion & Demotion
- Understanding Solace Delivery Modes: Direct Messaging vs. Persistent Messaging
- Understanding Solace Endpoints: Durable vs. Non-Durable
- Understanding Solace Endpoints: Queues vs. Topic Endpoints
- Understanding Solace Endpoints: Message Queue Access Types for Consumers
Explore other posts from categories: For Developers | Products & Technology



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.