The Benefits of Microservices Choreography vs Orchestration
Microservices architecture — a software design paradigm in which an application and business use case
Eventual consistency is a technique in distributed systems that ensures data consistency and availability by allowing multiple processes to communicate asynchronously, so errors can be resolved without bringing the entire system to a halt.
Anyone who has ever done yard work as part of a team can understand the power of eventual consistency in microservices. This starts with understanding the fact that having multiple people work independently on specific tasks is the best way to complete a complex job, because the overall process doesn’t grind to a halt when something goes wrong with one task. While it might not be optimal for the rose bushes to remain untrimmed while everything else moves along, you know it – and therefore the whole job – will get done…eventually.
Aiming for eventual consistency in microservices works the same way: instead of insisting that microservices fire in a specific sequence and either complete or fail together, you let them run in parallel at their own speed, while making sure your architecture doesn’t let tasks fall through the cracks. If you have a solid, scalable architecture in place, you can be sure that eventually all the various tasks will be in the same (consistent) state of completion. This is in stark contrast from strong consistency, where all microservices operate under the same transaction and either commit or rollback at the same time.
Eventual consistency can take some getting used to, but it provides crucial flexibility in a world where many enterprises operate around the clock and rely on services that can’t be up and running 24/7. In the real world (and in microservices architecture) the concept of eventual consistency makes it easier to accommodate such systems and overcome obstacles.
You’ll face two key challenges when designing for eventual consistency:
How do you overcome these two challenges? In microservices and yardwork alike, it’s all about communication.
Your successful implementation of eventual consistency in microservices largely depends on how your microservices interact with each other. In the microservices world, many organizations rely on synchronous, one-to-one interaction style, with one microservice directly calling another, usually via REST
Synchronous communication is simple and straightforward because you know exactly what will happen, in what order, and who is talking to whom—microservice A talks to microservice B, it’s right there in the code. However, REST struggles in a couple key areas:
Since microservices don’t usually store state either, that lack of persistence is a challenging problem to overcome. In theory, it’s easy to implement a chain of synchronous tasks –each task leads immediately into the next task. But when something unexpected happens, watch out.
The other choice is to connect microservices asynchronously through an event-based architecture. Rather than having microservices directly interact with one another, Microservice A publishes an event to an event broker. The event broker then takes the event and distributes copies to individual queues watched by other interested microservices. Microservice B (and possibly C, D and E) pick up their copy of the event and do their thing.
Here’s how an event broker simplifies eventual consistency, and error handling in general:
To revisit my yardwork example, supervisor lead landscaping crews and won’t let each worker forget what they’re supposed to do as part of making your yard look more inviting. If some tasks aren’t getting done, you can be sure this supervisor will remind the lagging workers to wrap things up and take action if there’s some reason things aren’t happening.
Sticking with that example, let’s analyze two approaches: RESTful and event-driven. First, let me explain the situation and the tasks (microservices) that needed to be completed.
Earlier this year, I sent a desperate email to my local garden center, appropriately entitled “Ugly Area by Front Step”. As I mentioned, the state of our front yard justifiably concerned my partner, because it looked like squatters were occupying our home. The reply from the garden center indicated they were shocked and dismayed by the images I had attached:

As a proud homeowner, I resolved to get things back on track, which in my mind involved three tasks:
1) repair the sprinkler system
2) spread mulch over everything dead, and
3) plant the world’s most vigorous plants.
It’s important to remember that a half-done job would look worse than if I had never started—it might take some time, but it all had to get done eventually.
In the meantime, the world had taken a turn for the worse; with the emergence of COVID-19, making a trip to the local garden store was no longer an option. This meant it would take longer for supplies to arrive, if they showed up at all. That threatened the entire project.
Let’s take some liberties and call my front yard situation a use case called “Fix Front Yard” and decompose my lawn maintenance into three distinct microservices called RepairSprinkler, SpreadMulch, PlantVigorousPlants, tied together into a front yard service called Do work. Like many enterprises, let’s link them together synchronously, like they would be with REST.

Imagine this scenario: In a stroke of luck, I’m able to successfully repair the sprinkler and spread the mulch. But then my luck then runs out. Border restrictions prevent all pachysandra plants (considered by many to be unkillable) from making it across the border. In the real world, the lawn threatens to remain permanently “half done.” In the microservice world, we’ve made our enterprise “inconsistent”.
Fighting back from an inconsistent state in a synchronous enterprise is a challenge. Here are a couple options:
Let’s look at a couple of these in detail:
Some architects select a two-phase commit (XA transaction) that spans multiple microservices, in turn spanning databases and/or transaction monitors. For good reason, microservice dogma advocates avoiding two-phase commits for two reasons: First, even on a local network, they’re slow, which is death for the modern enterprise. Second, they add complexity to the implementation and can hold threads and connections open for extended periods of time.
In our lawn example, having a transaction span all three microservices means that the “exception” within PlantVigorousPlants, forces both RepairSprinkler and SpreadMulch to “roll back” their work. This is challenging and counterproductive: it is hard to remove mulch and why would you break the irrigation system again? But to establish strong consistency, that’s what it takes.

As an alternative to using two-phase commit, some architects choose to roll back changes by introducing local state logic and custom coding failure compensation. This again flies in the face of the microservice dogma that microservices should be stateless, and it may not even be possible if the exception scenario means you can’t reach a database or disk.
Another approach would be to keep the sprinkler repaired and the dead stuff mulched, but return an exception back to the user of “Do Work” indicating that the plants weren’t available so try again later. This approach works only if all the services are “idempotent”. In other words, the services can be re-run multiple times with the same result. If RepairSprinkler and SpreadMulch aren’t idempotent, then you’ll douse the sprinkler pipe with PVC glue and stack the mulch up to the roof line. It better be idempotent.
Even if you can finagle the necessary error handling, the elegance of your microservice architecture takes a major hit with a RESTful approach. Implementing complex error handling distracts coders from the business logic that should be at the core of a microservice. Instead of having a single purpose, the microservice needs to include logic about what service to call next and what to do if that service fails (or a service three down the line).
There’s gotta be a better way to fix a yard!
Let’s keep the three distinct yard care microservices, but instead of tightly coupling them, let’s have them process asynchronously, as they’d be with event-driven architecture. The “Do Work” service still receives a REST request, but instead of initiating a chain of synchronous REST calls, it publishes an event to an event broker.
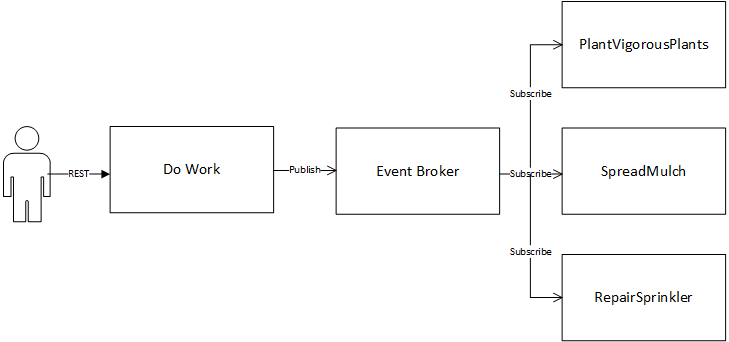
Rather than a brittle chain of microservices, each microservice now looks at the event and says “Ahhh, I know how I can help that situation.” However, once again, I complete the sprinkler repair and the mulching in short order, but the border holds up my unkillable plants, leaving the final stage of the project incomplete. Since the event broker handles state and persistence, we can leverage eventual consistency in microservices in this example. The event broker simply stores failed jobs, waiting for new inventory to arrive. This resolves several of the challenges with our REST example:
As I said before, in domestic life and in microservices, communication makes all the difference. REST complicates error handling, and in the worst cases loses messages. That makes a post-apocalyptic front yard pale in comparison. Meanwhile, event-driven architecture eases you into a world of eventual consistency in microservices, which can make your error handing and disaster recovery much easier.
And if you’re wondering, my front yard is not yet suburban perfection, but it’s definitely getting better. I think our first post-COVID dinner party will be a roaring success.
More resources to check out:
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.