Streaming Data Between kdb+ and PubSub+
Solace has been serving the financial industry with its industry leading event broker, PubSub+, for
Things were simpler a few years ago when all of your applications were running on-premises. Sure, you had to manage all that yourself, but it was easy to deploy your applications on your finite number of servers. Now cloud computing has taken off and you don’t have to worry about managing your own datacenter anymore, at least not to the extent you used to earlier. Many companies, especially startups, have decided to embrace the cloud, but enterprises still have an on-prem datacenter for critical applications and sensitive data, with newer and less sensitive applications moved or moving to the cloud.
Similarly, your kdb+ stack used to be on-premises, running on powerful servers spread across the world to capture market data from different markets. But slowly, you are realizing that there may be a better way to manage your kdb+ stack. Maybe not all components of your kdb+ stack need to be on-prem, and maybe other applications across your organization might benefit from having access to the data in your kdb+ database.
It can bring some challenges, however. For example, do you manage data transfer between your q applications running locally on-prem and on the public cloud? How do you then make this data available to other applications in hybrid/multi-cloud systems?
I told you life was much simpler before! But don’t worry, because in this post I am going to pull together different modules I have been working on in the last few weeks and months and show you how you can easily stitch your applications together in a robust, uniform, and secure manner.
First I’ll introduce a market data flow that consists of three different components. I have already written individual posts about each of these components that go into detail on how they work and how to set them up. Please have a look at them to get a better understanding of each component. These components are:
Note that this setup doesn’t just use different languages and databases, but the three components are deployed in three very different environments. To stitch these different applications and environments together, we will be using Solace PubSub+ Event Broker. This is what our architecture will look like:
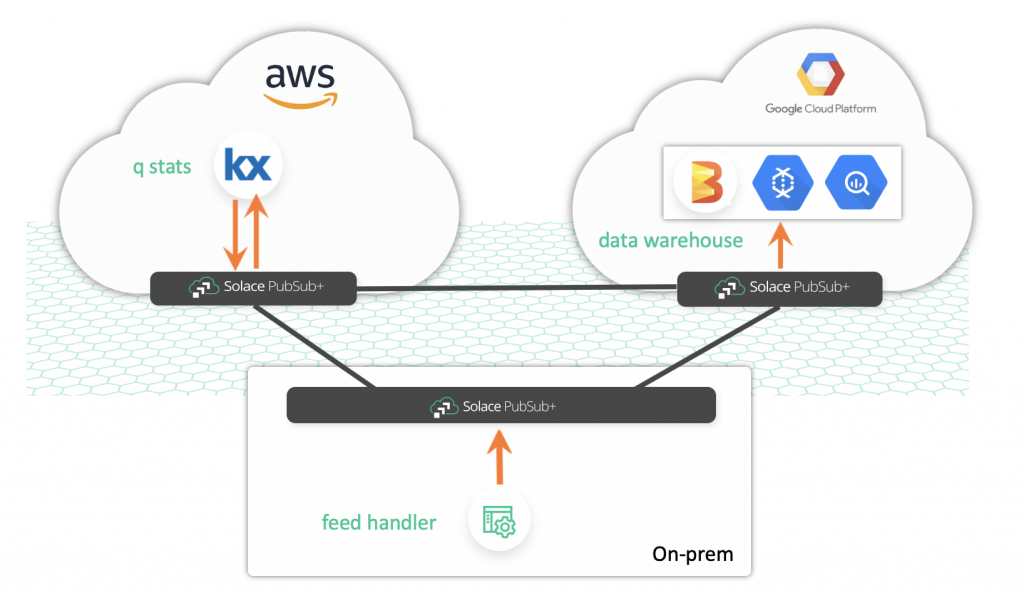
While I had the option to just have a single PubSub+ Event Broker deployed on any of the major cloud providers via Solace PubSub+ Event Broker: Cloud and have all three processes use the same broker, that’s not how you’d implement such a system in production. In a production environment, you’d typically have multiple deployments of the broker in different environments and regions. Hence, I decided to have three deployments of PubSub+ Event Broker:
That’s great, but how do you connect all these brokers? By building an event mesh that takes advantage of a PubSub+ feature called dynamic message routing (DMR). With PubSub+ brokers linked together and DMR enabled, applications can continue to publish to their local instance, but can subscribe to messages being published to topics on other brokers. This enables the stats process to consume raw market data in AWS that is being published to a local broker.
I have gone ahead and connected the three brokers and started each of the three processes.
My feed handler is publishing simulated market data for a handful of securities from different exchanges:
As you can see, currently, our feed handler is publishing data for securities from the US and UK exchanges (since I am running the feed handler during their market hours). However, I am only interested in generating stats for securities traded in the US. So, in my market_data queue, I have used PubSub+’s wildcard filtering capability to subscribe to this topic: EQ/marketData/v1/US/>. This only enqueues US market data into my queue and saves me the trouble of having to filter these records myself in my q stats process.
In parallel, I have my q stats process running on AWS and connected to a different broker deployed in AWS. Here is the output of my stats process for each symbol:
These stats are computed every minute and are published to new dynamic topics with the following topic heirarchy: EQ/stats/v1/. For example, INTC’s stats are published on EQ/stats/v1/INTC.
A separate queue called stats is subscribed to EQ/stats/> so it is capturing all stats messages that our stats process is publishing.
My third process is a Beam/Dataflow pipeline running in GCP which is consuming all stats messages from our stats queue, parsing them, and then writing them to BigQuery. Here is what that pipeline looks like in Dataflow:
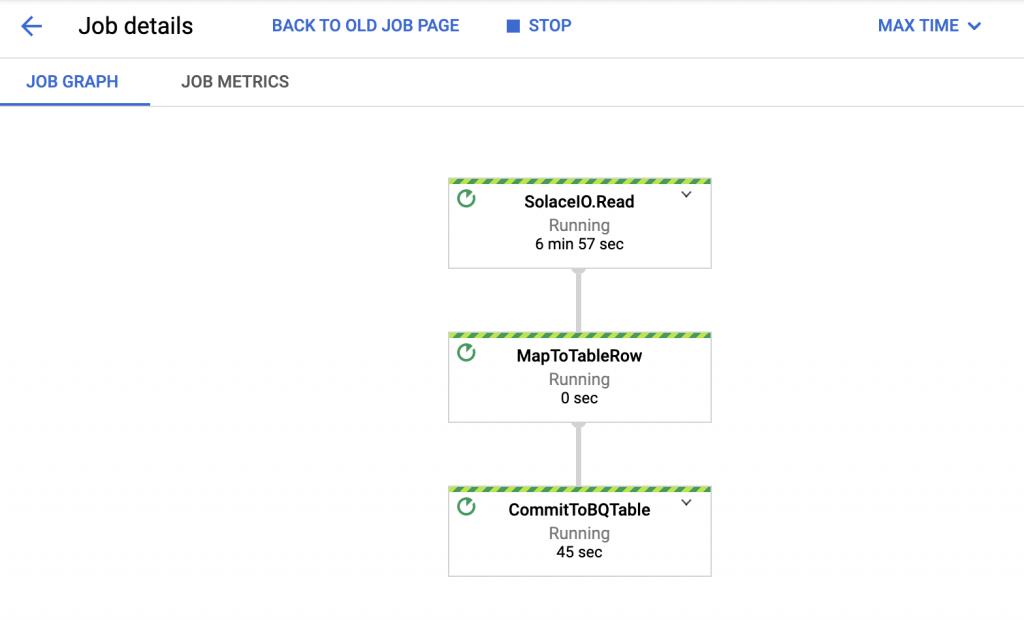
And here you can see that stats are being written into BigQuery:
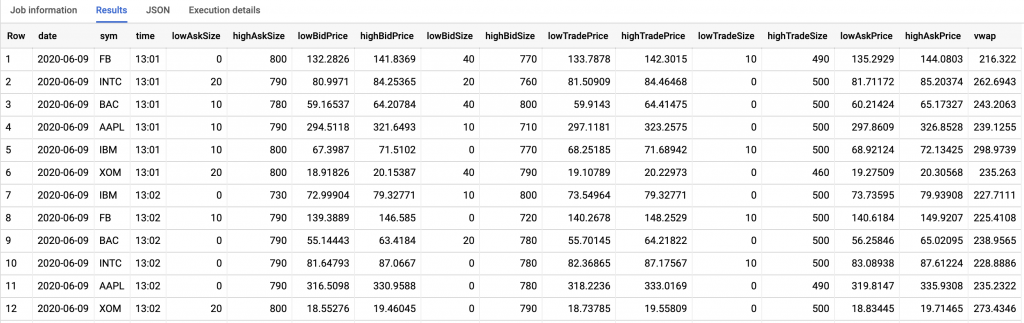
Voila! Stats data is being inserted into BigQuery, and you can also see that it only includes stats for US stocks because I used PubSub+’s wildcard filtering earlier in the q stats process.
As other application architectures have evolved in the last few years, kdb+ architecture has also evolved. Applications running in hybrid/multi-cloud environments and with different runtime environments can communicate with each other using PubSub+ Event Broker. In this post, I showed how a Java feed handler running on-prem can send raw market data prices to a q stats process which in turn sends it to BigQuery through PubSub+.
This architecture can evolve further to add multiple different components such as a machine learning algorithm in AWS or a visualization application running in Azure on top of data streaming through PubSub+.
I hope you enjoyed this post. Feel free to leave a comment in our developer community if you have any questions.
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.


